By Oliver Folba
A reality that startups must face is that different growth stages require different CRM systems. Switching to a more powerful CRM system such as Salesforce seems like a natural next step for them.
We recently migrated the sales data of one of our ventures from Pipedrive to Salesforce. In this blog post, we want to share some best practices, our learnings and highlight some issues we ran into that others can avoid.
General process
The migration process can be split up into three phases: Preparation, data export and transformation, and finally the data import.
First, you should prepare the migration as diligently as possible. Get a good understanding of the data structures and try to anticipate problems that might occur down the road. Think about your sales process and set up your Salesforce organisation accordingly.
Second, export your data from the source system and transform them into the right format for the import. As you will likely need several attempts before you get this right, we recommend using scripts to speed up this process.
Third, you will need to import the data generated by the second step into Salesforce. Salesforce provides several interfaces to import data, we used the Data Import Wizard and the Dataloader during our migration.
Preparation
In order to prepare the migration, we recommend you do the following four things:
1.) Check the current data modeling in Pipedrive
First, it is important to understand the modeling of the entities within Pipedrive. The main object in Pipedrive is a “deal” that moves through the different “stages” of a “pipeline”. So far so trivial. A deal can be associated with an organisation, but this is not mandatory. Watch out for these deals. The same goes for activities: Activities can be associated with a deal, a person or an organisation. This can make it hard to consolidate all information related to a deal in one place. We, therefore, recommend to spend some time with your Sales reps to understand the different ways different people actually use the tool as opposed to how they are supposed to use the tool (one of our sales colleagues used the subject line of an activity to store additional information instead of using the note field, e.g.). Never underestimate a person’s creativity when it comes to using free text data input fields.
2.) Clean up data in Pipedrive
During our migration, we skipped this step and it came back later to bite us several times. Thus we cannot stress enough the value of cleaning up as much data beforehand as possible. We recommend using the python snippets at the end of this article to download all deals and organisations via the API. Then you can identify issues potential issues easily in a Jupyter Notebook and fix them in Pipedrive. In particular, you want to look for
– deals without an organisation (create an organisation for these deals, because in Salesforce every opportunity needs to be linked to an account)
– persons associated with a deal, but not the organisation the deal belongs to
– duplicates records (especially persons or different versions of the same organisation)
– funny characters in names
3.) Set up data modeling in Salesforce
Migrating to a new CRM tool is a great chance to evaluate your current sales process setup and improve it. Are the stages we are currently using in our sales funnel still making sense? Which information do I want to store on the company/account level rather than on a deal/opportunity? This is again something you should determine in close cooperation with your sales reps.
To ensure a smooth migration process we recommend to create a custom field on all Salesforce objects that stores the Pipedrive Id. You can delete this field after the migration was successful, but such a field will come in handy later.
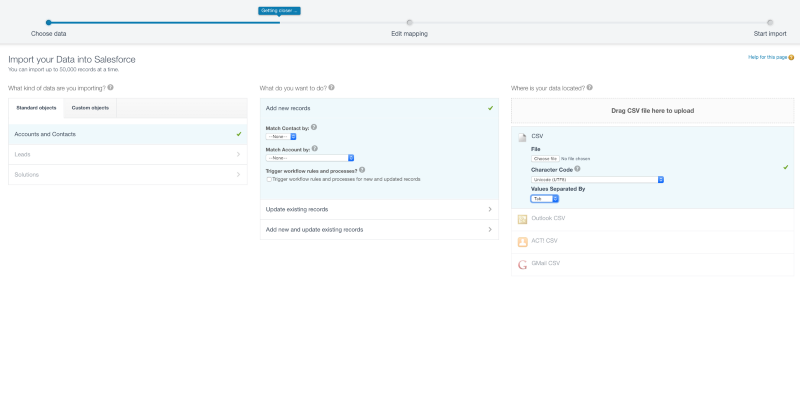
4.) Create a mapping between Pipedrive data and Salesforce data
Setup a clear mapping between Pipedrive field values and Salesforce field values, especially if you change the data modeling. Make sure that this list comprehensive by downloading unique Pipedrive field values via the API rather than taking them from a drop-down menu in the UI. Historic data may have a different field value that the current field list does not include.
Export Pipedrive Data
After the preparation, the actual migration can begin. Again, and we cannot stress this point enough, we recommend using code to retrieve the raw data from Pipedrive and to transform them into the right format. The main reasons for this are evident:
- Data availability: Not all fields of an object are available for export via the UI
- Reproducibility: Yes, even after reading this blog post you will need several upload attempts. While technically possible, you simply don’t want to do the kind of transformations necessary by hand in Excel and them do them all over again for the next attempt
- Documentation: If after some time some questions arise about how specific objects were transformed, a well-commented script goes a long a way in documenting the process
The first step then is to download your organisations, persons, deals, and activities from Pipedrive via the Pipedrive API. Then you want to apply the mapping of field/column names that you devised during the preparation phase. Make sure all your date and timestamps are in a format that is accepted by Salesforce. If you want to convert a free text field in Pipedrive to a select field (pick list) in Salesforce, this is the time to do it: Create a mapping dictionary and use the replace function of the pandas package to apply the mapping.
After you have wrangled your data into the correct format, you can export your data to a csv file that you then can upload to Salesforce. We recommend using a tab-separated, utf8 encoded csv file in order to avoid locality issues. If you should feel the urge to open this csv file in Excel, please note that Excel expects csv files to be encoded differently. In order to avoid some funny looking characters, either use the import function in Excel or open the csv with Google Sheets.
Import Data to Salesforce
Now we are finally ready for the big moment of truth: the import of the data to Salesforce. It is advisable to do some test import in a sandbox environment first until you have understood the inner workings of Salesforce.
We start with the accounts and contacts and use the Salesforce Data Import Wizard. The settings are pretty straightforward: Select the entity you want to import and choose the file type and encoding. After that, the Wizard suggest a mapping based on the column names found in the csv import file. Luckily we have renamed our columns in our script to exactly match the new Salesforce field names, so that we don’t need to waste a lot of time manually assigning each column to the corresponding field.
Next, you need to export all of the newly created accounts in order to obtain the Ids that Salesforce assigned to them (via the “report” functionality in Salesforce). These Salesforce Ids need to be mapped to the corresponding organisation ID in Pipedrive, so that we then can link each opportunity to the correct Salesforce account. If you created a custom field in Salesforce on the account to carry over the Pipedrive organisation ID, this mapping process becomes much much easier. Again, we recommend doing the mapping via a script.
Once you got the right Salesforce Account Id on each Pipedrive deal you can import them as Opportunities into Salesforce. Unfortunately, this is not possible via the Data Import Wizard. Instead, you need to use the Dataloader. If you want to carry over the original creation dates of your opportunities, make sure to enable the “set audit field option” in your Salesforce preferences.
Now that you have successfully imported the Pipedrive deals, next up are the Sales activities. Salesforce distinguishes between tasks and events, so please make sure to categorize your Pipedrive tasks accordingly. Via the “WhoId” field you can link a sales rep and via the “WhatId” you can link an activity to either an Opportunity or an account. This is a good point to think about at which entity which activities should be stored and to link past activity data to another entity, if so desired.
Conclusion
Congratulations, you have successfully migrated your sales data from Pipedrive to Salesforce! Make sure that all the data is complete and that all entity associations are correct.
A migration from Pipedrive to Salesforce requires rigorous preparation and some technical skills as well as good communication between the Sales Team and the person actually migrating the data. But we hope that this blog post shows that it is possible to pull this off in house without the need for expensive external consultants.
Appendix: Useful Code Snippets
import urllib3
from pandas.io.json import json_normalize
import pandas as pd
import os
http = urllib3.PoolManager()
api_token = "&api_token=" + os.environ['PIPEDRIVE_API_KEY']
### Deals
def download_deals(start_number):
"""Download all deals with a specified pagination start"""
limit_number = str(start_number + 500)
url = "https://api.pipedrive.com/v1/deals:(id,title,org_id:(value),org_name,value,activities_count,pipeline_id,stage_id,status,add_time,won_time,owner_name)?start="
limit = "&limit=" + limit_number
start = str(0+start_number)
r = http.request('GET', url+start+limit+api_token)
data = json.loads(r.data)
additional_data = json_normalize(data["additional_data"])
more_data = additional_data["pagination.more_items_in_collection"].values[0]
deal_data = json_normalize(data['data'])
return more_data, deal_data
def download_all_deals():
"""Wrapper to download all deals"""
more_deals, deals = download_deals(0)
i = 500
while more_deals:
more_deals, deal_data = download_deals(i)
deals = deals.append(deal_data)
i += 500
deals.reset_index(inplace=True, drop=True)
return deals
### Organisations
def download_organisation_fields():
url = 'https://api.pipedrive.com/v1/organizationFields?'
r = http.request('GET', url+api_token)
field_data = json.loads(r.data)
fields = json_normalize(field_data['data'])
fields.columns = ['field_name' if x=='name' else x for x in fields.columns]
return fields
def download_organisations(start_number):
"""Download basic information about all organisations"""
limit_number = str(start_number + 500)
url = "https://api.pipedrive.com/v1/organizations:(id,add_time,company_id,name,owner_id:(id,name),address)?start="
limit = "&limit=" + limit_number
start = str(0+start_number)
r = http.request('GET', url+start+limit+api_token)
data = json.loads(r.data)
additional_data = json_normalize(data["additional_data"])
more_data = additional_data["pagination.more_items_in_collection"].values[0]
org_data = json_normalize(data['data'])
return more_data, org_data
def get_all_organisations():
"""Wrapper to download the data of all organisations"""
more_organisations, organisations = download_organisations(0)
i = 500
while more_organisations:
more_organisations, org_data = download_organisations(i)
organisations = organisations.append(org_data)
i += 500
organisations.reset_index(inplace=True, drop=True)
return organisations
### Activities
def download_users():
"""Download all users"""
url = 'https://api.pipedrive.com/v1/users?'
r = http.request('GET', url+api_token)
user_data = json.loads(r.data)
users = json_normalize(user_data['data'])
return users
def download_activities(start_number, user_id):
"""Download all the activities of a single user from a specified pagination start"""
limit_number = str(start_number + 500)
url = "https://api.pipedrive.com/v1/activities:(id,user_id,person_id,done,note,type,due_date,duration,add_time,update_time,marked_as_done_time,deal_id,org_id)?start="
user = "&user_id=" + str(user_id)
limit = "&limit=" + limit_number
start = str(0+start_number)
r = http.request('GET', url+start+user+limit+api_token)
data = json.loads(r.data)
additional_data = json_normalize(data["additional_data"])
more_data = additional_data["pagination.more_items_in_collection"].values[0]
if data['data'] == None:
activity_data = pd.DataFrame()
else:
activity_data = json_normalize(data['data'])
return more_data, activity_data
def get_all_user_activities(user_id):
"""Download all the activities of a single user"""
more_activities, activities = download_activities(0, user_id)
i = 500
while more_activities:
more_activities, activity_data = download_activities(i, user_id)
activities = activities.append(activity_data)
i += 500
return activities
def get_all_activities(ids):
"""Download all activities of all users"""
activities = pd.DataFrame()
for i in ids:
activities = activities.append(get_all_user_activities(i))
activities.reset_index(inplace=True, drop=True)
return activities
Code language: PHP (php)