By Cyprien Marcos
If you’re familiar with Google Analytics and Google Tag Manager, you know how easy it is to define, track and attribute a website conversion. However, you’re probably also aware that you can only attribute the last touchpoint. You only get aggregated results — no detailed breakdowns.
The problem — you can only attribute the last touchpoint in Google Analytics
This is not enough. A user journey can be very complex, and it’s unwise to make major decisions based only on the last touchpoint. Why? Let’s look at a simple example. At Project A, we recently had to deal with this very issue when designing reports for our talent acquisition team.
Our use case: a talent acquisition funnel
The journey
Like most of the companies, we have a careers page on our website, where we receive applications and we wanted to attribute them to the right source.
Here’s an example of a journey that a user took before they submitted an application:
- Session 1 on 02/09/2020
source: LinkedIn Paid Social
events completed: Podcast abc played - Session 2 on 28/09/2020
source: Organic
events completed: Job page xyz read - Session 3 on 03/10/2020
source: Direct
events completed: Job application submitted for xyz
The user had three sessions that came from three different channel groupings (LinkedIn Paid Social, Organic and direct). Furthermore, two important events happened before they submitted their application in the last session: they played a podcast and read the job description in two previous sessions.
What would we see in a last-touch attribution report?
If we followed the standard tracking and reporting process in Google Analytics, the application would be attributed to 100% to the direct channel in the last session. We wouldn’t be able to correlate the application with the previous sessions (coming from LinkedIn and search) or events (listen and reading). Given what the user did before they applied, we know that this doesn’t tell the full story. Let’s try to improve the reporting with a simple implementation!
Implementation summary
- Use GTM to parse _ga and _gid cookies as UserID and JourneyID for all sessions
- Send them to GA as custom dimensions
- Define the conversion to track in GTM
- Pull GA data into a Jupyter notebook: UserID, JourneyID, UTM parameters, conversions
- Model the data in python and apply multi-touch attribution
- Push the data back to your data source and visualise conversion insights with multi-touch attribution
The implementation
Let’s implement a hack and set up a very basic multi-touchpoint attribution model. To do so, we’ll leverage the _ga and _gid cookies that are set by Google Analytics and use them as custom dimensions. Afterwards, we’ll model the data from Google Analytics to get an attribution model that makes more sense.
What are the _ga and _gid cookies from Google Analytics?
Google Analytics depends heavily on cookies to track users. It sets different kinds of third-party cookies when a user browses on your website. Among them:
- The _ga cookie that expires after 2 years and used as visitor identification
- The _gid cookie that expires after 24 hours and used as user journey
We’ll treat the _ga cookies as a User ID and then track the different user journeys with different _gid cookies which we’ll treat as a Journey ID.
How to define these cookies as a custom dimension
The whole setup relies on the two cookie values that are saved for each session and used as custom dimensions in Google Analytics.
- Parse both cookies on GTM with a custom variable
To do so, we’ll set up two Custom JavaScript variables.
- UserID containing the _ga cookie
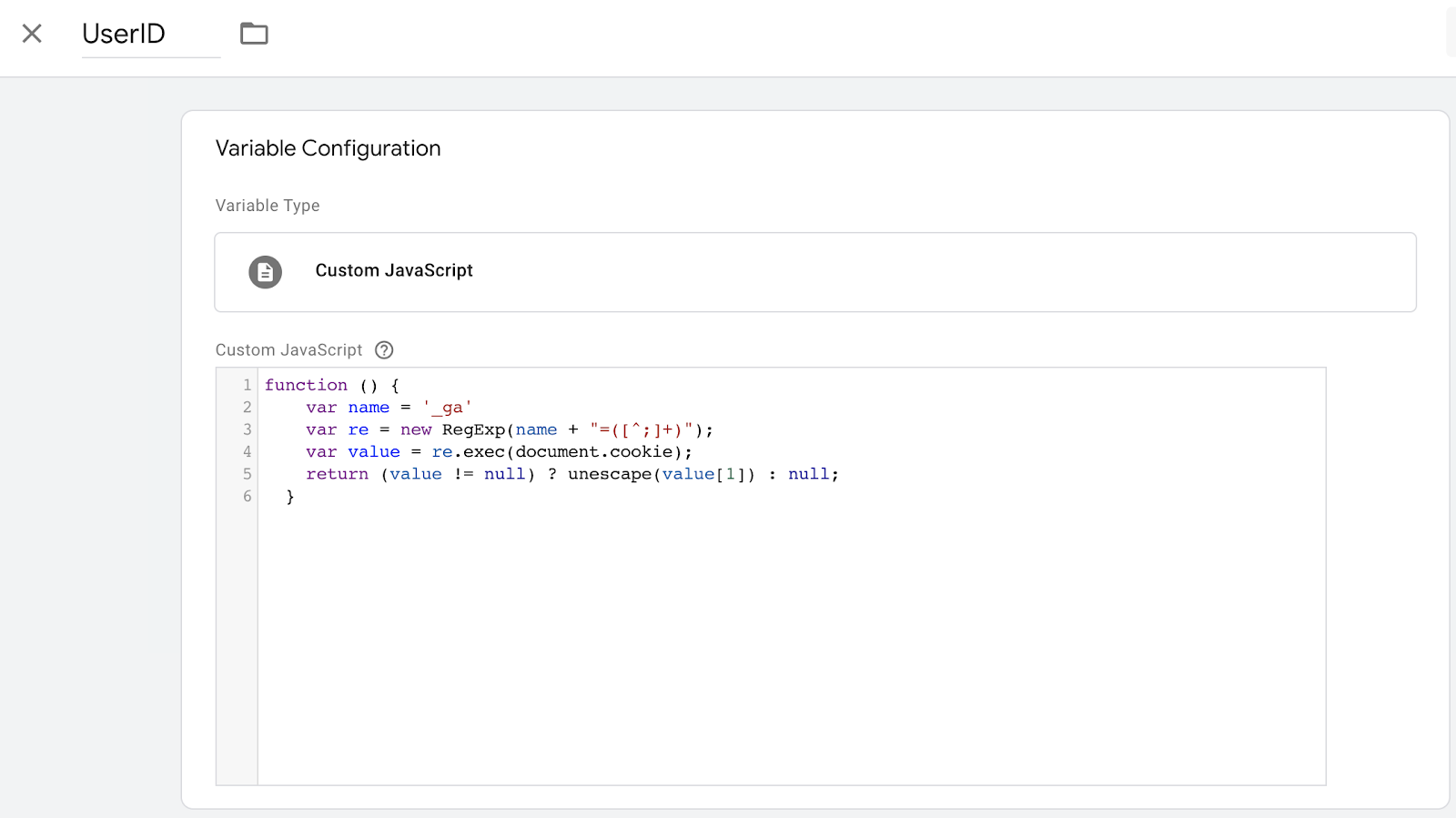
function () {
var name = '_ga'
var re = new RegExp(name + "=([^;]+)");
var value = re.exec(document.cookie);
return (value != null) ? unescape(value[1]) : '(not set)';
}Code language: JavaScript (javascript)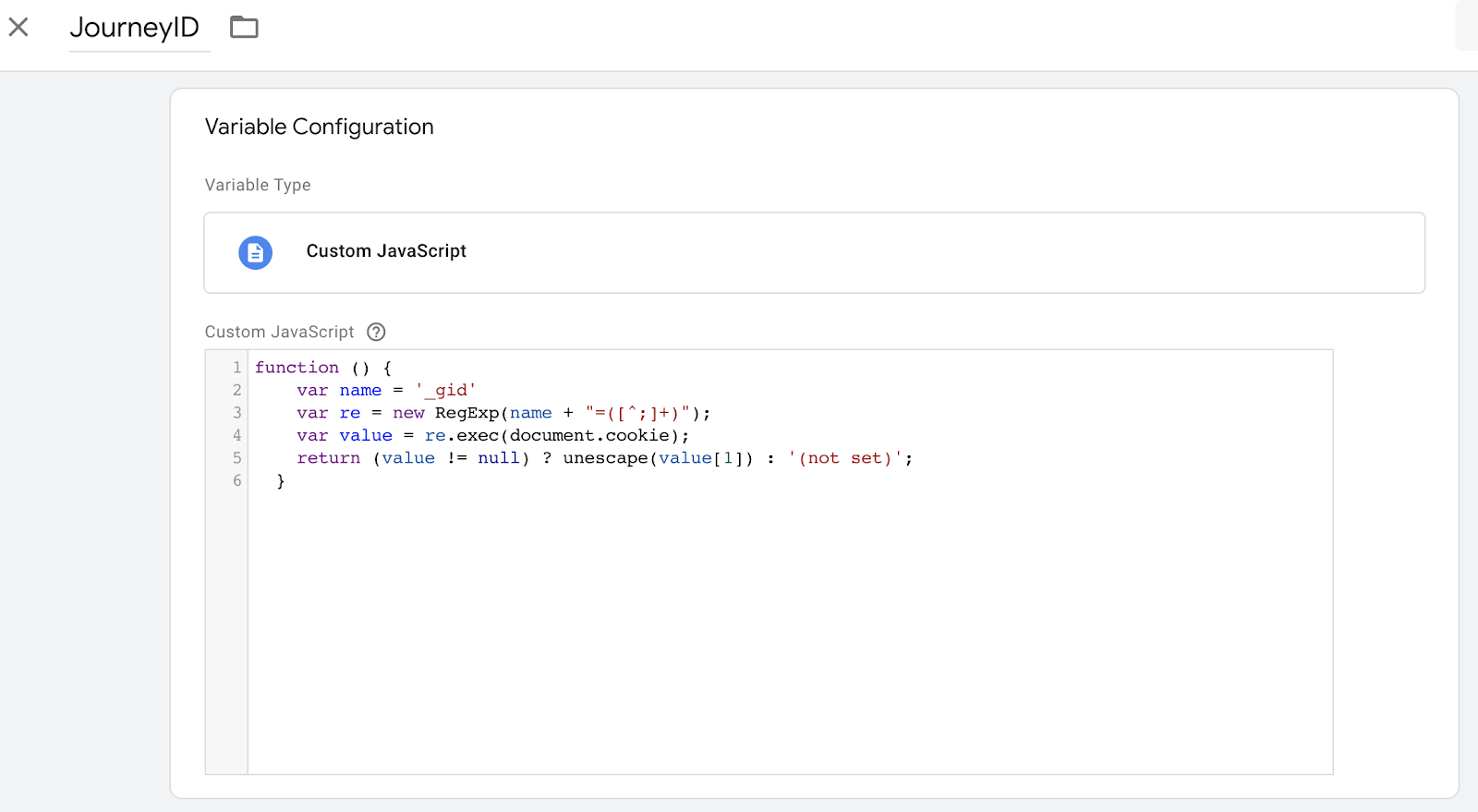
function () {
var name = '_gid'
var re = new RegExp(name + "=([^;]+)");
var value = re.exec(document.cookie);
return (value != null) ? unescape(value[1]) : '(not set)';
}Code language: JavaScript (javascript)Both values are now parsed for each user and will be used to populate Google Analytics custom dimensions.
- Host both variables as Custom Dimensions in Google Analytics
To host the parsed values, we need to create two custom dimensions. Follow these steps from your Google Analytics account:
- Got to Admin > Property > Custom Definitions > Custom Dimensions
- Click on + New Custom dimension, you should have the following screen:
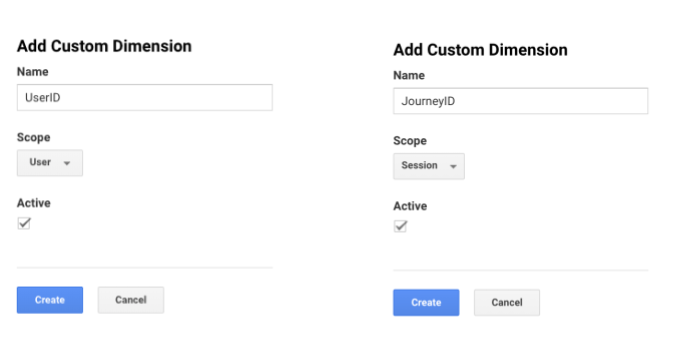
- Create two different custom dimensions for each variable: JourneyID (Session) and UserID (User). Click on Create.
- You should have the following screen:
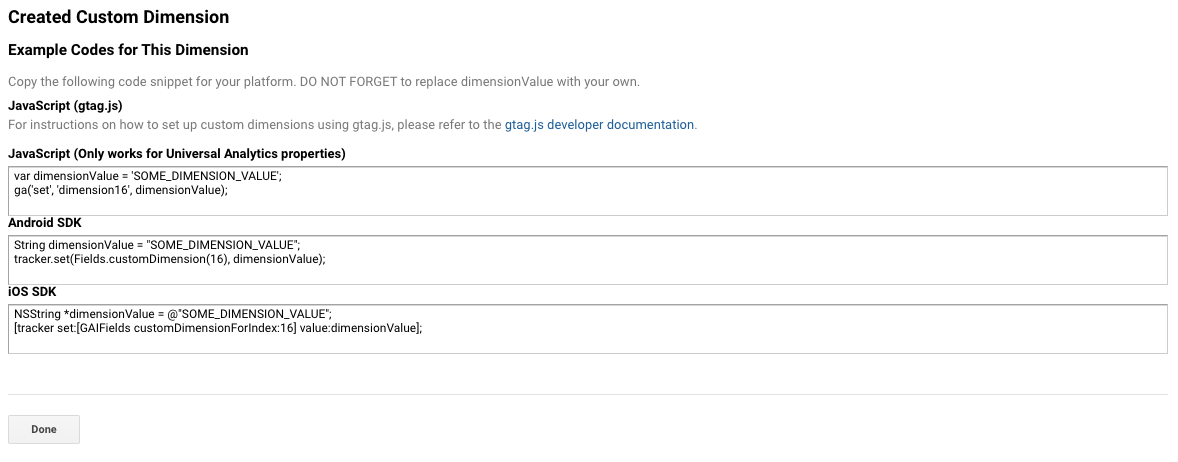
- Click Done.
You’ll need the dimension value (here 16) to send the values to the right custom dimensions from GTM.
Now that our custom dimensions are created, we just have to populate them with the two variables that we created in GTM.
- Send values from the browser to Google Analytics
To do so, we’ll open Google Tag Manager and add the two variables as custom dimensions to the Google Analytics settings variable.
NB: To make this work for all Google Analytics tracking, we recommend that you deploy Google Analytics via the Google Tag Manager rather than directly in your website’s source code. It’s very easy: here the official tutorial. Otherwise, you just have to follow the same process and add both custom dimensions to all the Google Analytics tags that you have on GTM.
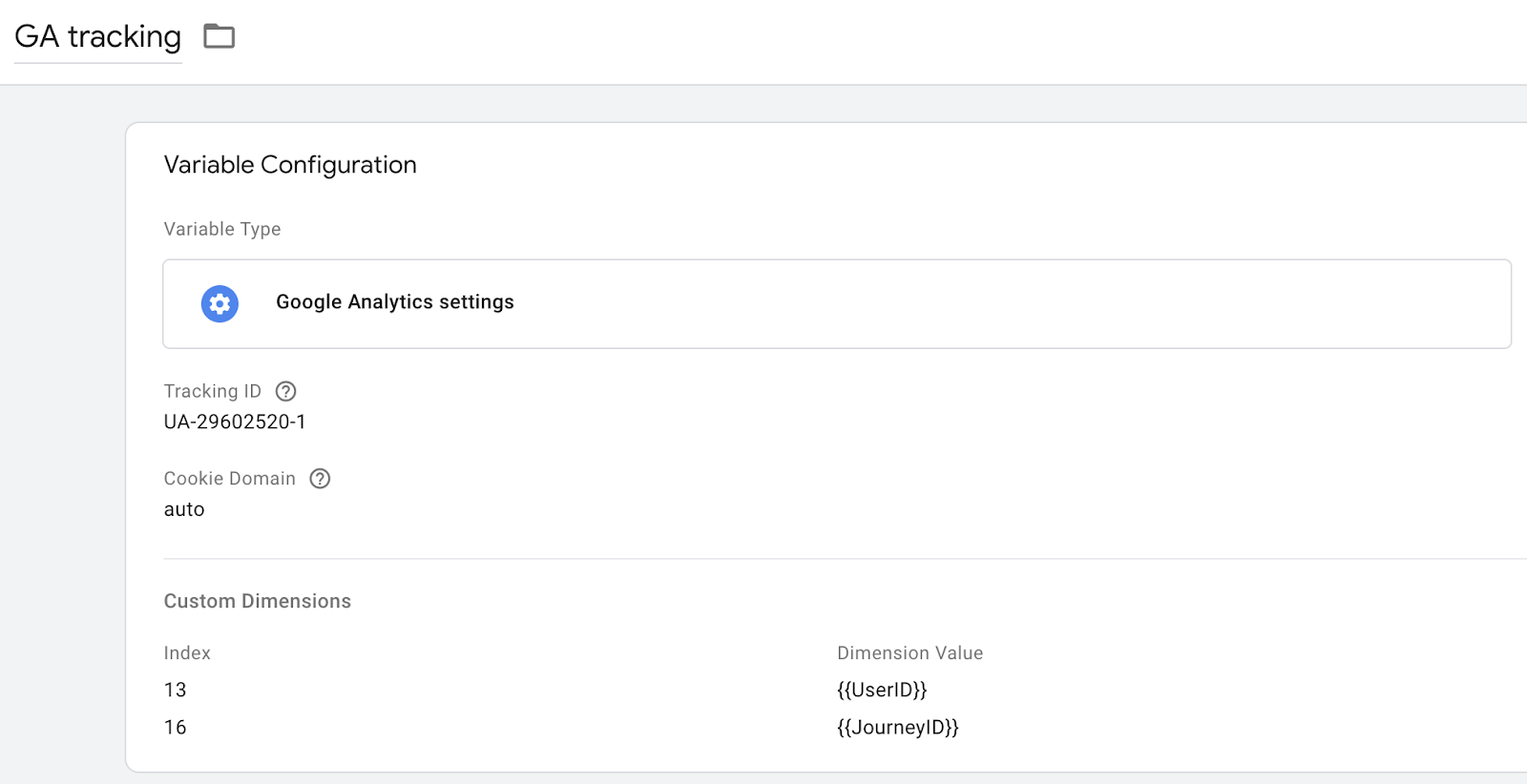
For this variable, we need to add the two custom variables that we created earlier:
- UserID and JourneyID variables in the Dimension value field
- The Index value from both custom dimensions (e.g. 16 for JourneyID)
Both cookies are parsed from the browser and sent to Google Analytics for any session on our website. This means that you’ll be able to use those IDs as dimensions for any analysis in Google Analytics.
We just need to set up the conversion tracking and our GA and GTM setup will be complete!
How to define the tracked conversion
- Define the Tag and Trigger in GTM
Let’s stick with the Talent Acquisition example, we want to track the job applications that were submitted. We need to create the following tag:
- Tag type: Google Analytics: Universal Analytics
- Track Type: Event
- Category, Action and Label: according to the naming convention (e.g. in our case the Label contains the Page Path, which contains the job name to which the user applied)
- Google Analytics settings: select the Google Analytics Settings variable that contains the 2 custom dimensions we defined earlier, in our case it’s the GA tracking variable
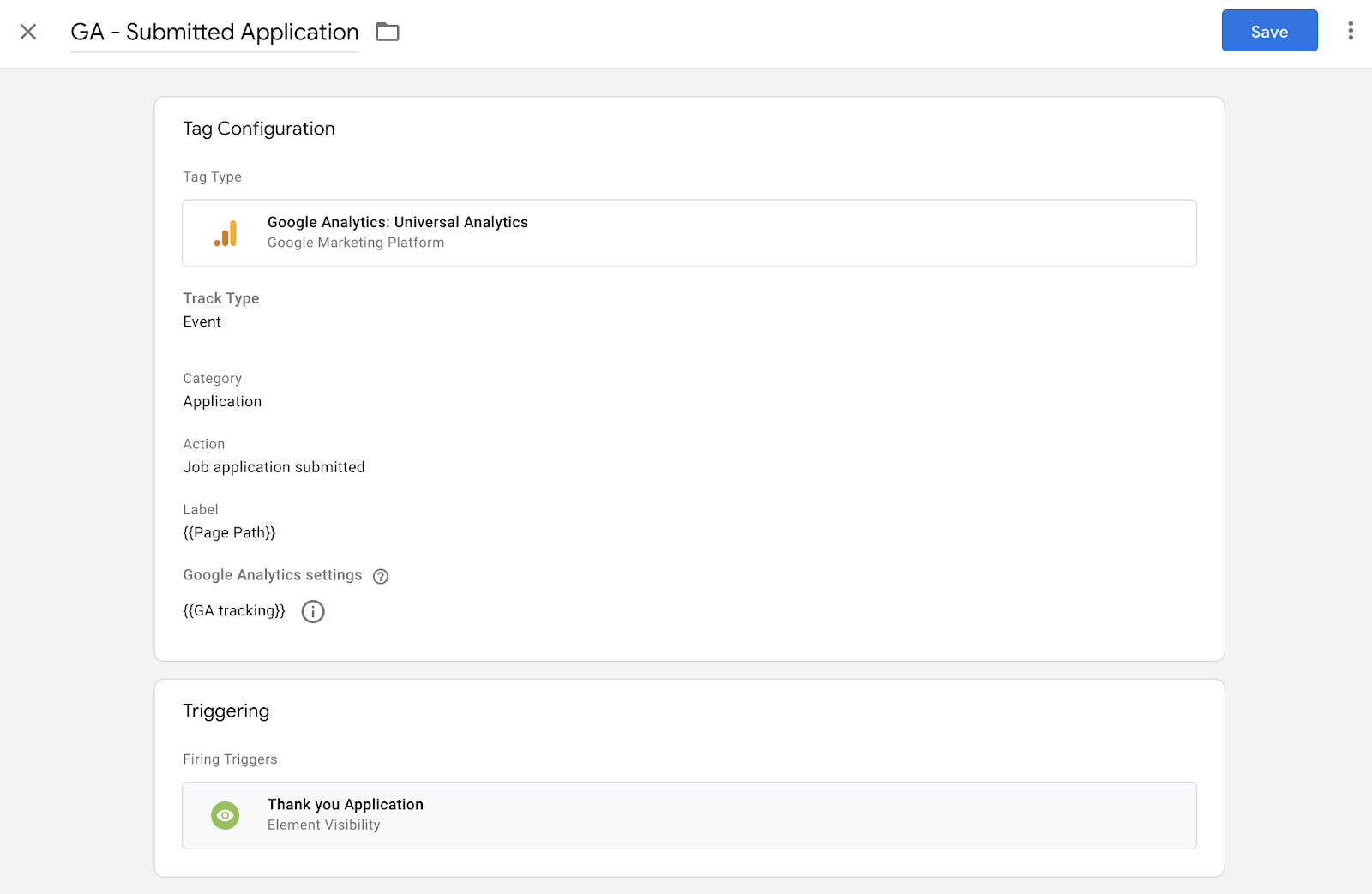
We can now add the right trigger that will fire for the given conversion. In our case, the trigger Thank you Application will fire for each application submitted.
- Host our event as a goal in Google Analytics
Now that we’ve defined a tag for the conversion, we need to host this event as a goal in Google Analytics. This will enable us to track the conversions on an individual level (thanks to our custom dimension) and give us the data we need for our multi-touchpoint attribution model.
- Got to Admin > View > Goals
- Click on + NEW GOAL
- Define the Name, in our case Submitted Application
- Select Event
- Fill in the Category, Action, Label and Value you defined in GTM, and according to your tracking requirements.
In our case, we have “Application” and “Job application submitted” and we leave the Label empty as we want to track all conversions and not filter for a specific job. - Specify whether you want to use the Event value as the Goal Value for the conversion (if you have an Event value)
- Click on Save
That’s it for the Google Analytics and Google Tag Manager setup!
This goal will now receive all the conversion events that we defined in GTM. We’ve met all the requirements to model our data and benefit from our multi-touchpoint attribution model. Before we jump into data modelling, let’s quickly make sure everything is working well so far!
Test all the requirements before modelling
To test whether the GA and GTM setup is working, you can set up a custom report with just the following dimensions and metrics:
When adding JourneyID as a secondary dimension, you should have the following report:
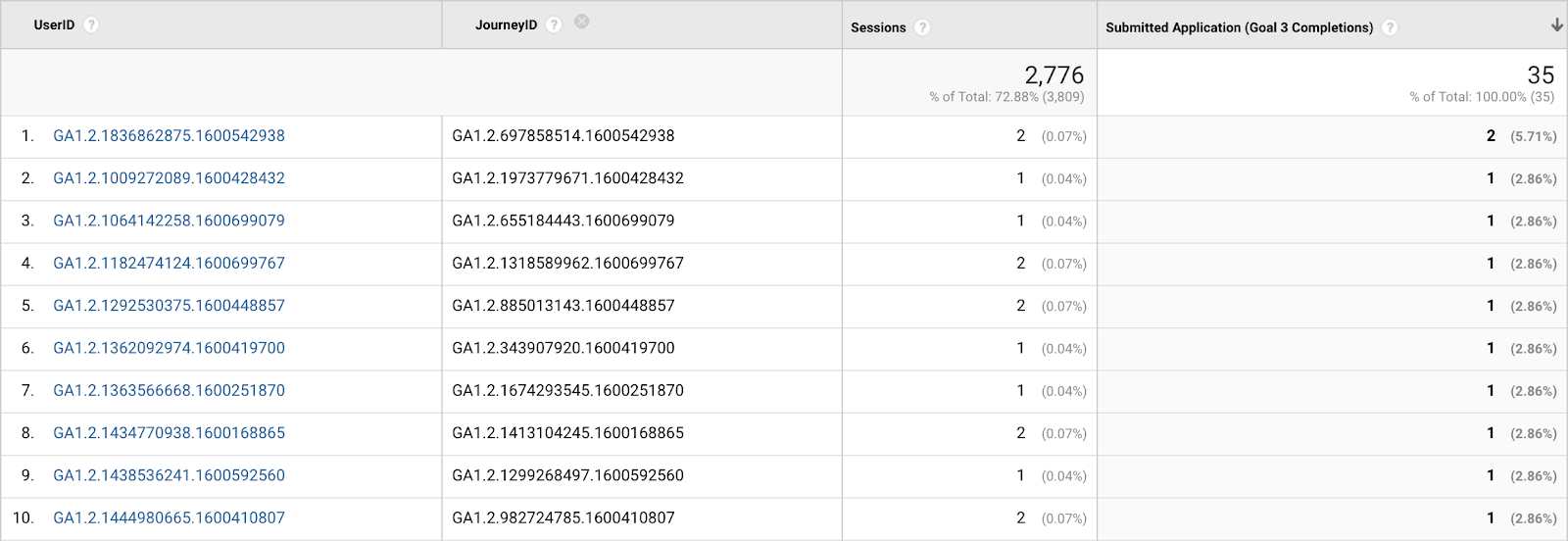
If the test is successful, you should be able to use both UserID and JourneyID in Google Analytics just like any other dimension. We can see that for each different combination of UserID and JourneyID, we have the number of sessions and the conversions.
After we combine these custom dimensions with other dimensions in Google Analytics, we’ll have everything required for further modelling.
Model the data in a Jupyter notebook
- Send Google Analytics data to your database
Now that everything is in Google Analytics, let’s pull all the raw data into your data source. In our example, we’ll use a Google Spreadsheet as our data source. From this data source, we’ll carry out further modelling and end up with a multi-touchpoint attribution model.
To meet our requirements, we’ll select the following in our data source:
- Dimensions: UserID, Source, Medium, Campaign, Date
- Metrics: Applications submitted (goal completions)
Whatever database you’re using, there are many different ways to send Google Analytics data to a wide range of destinations (BigQuery, Postgres, MySQL, Snowflake, Google Sheets…)
In our example, we used a small Google App Script to send data to our Google Sheet. Here a small list of methods to send your Google Analytics data to your destination:
This is how our data source looks now:

We basically have one row per journey, with the date, the user information (user_id and journey_id), the utm_medium and the number of submitted applications.
Now that we have the required data, we need to model it to distribute the conversions linearly between the different sessions and attribute all the involved channels. To make it clear, let’s have a look at two examples.
Conversion modelling: example 1
These are different journeys for one user. We can see that it’s always the same user_id with a different journey_id each time. Also, we can see that there was one conversion during the last journey. If we keep the dataset as is, we’ll have one conversion fully attributed to the referral channel.

Now our goal is to linearly distribute the conversion between all the channels and end up with the following modelled dataset:
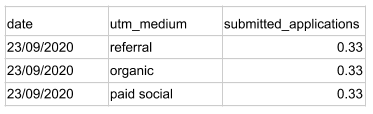
As a result, we have the conversion evenly distributed between the three different channels: referral, organic and paid social. This means all channels involved in the user journeys are taken into account. We also add the conversion timestamp to the rows.
Conversion modelling: example 2
Now let’s have a look at a slightly more complex use case. The user made the same number of journeys but with three conversions during two separate journeys: one conversion on the 21st of September and two conversions on the 23rd of September.

We’ll basically isolate each conversion and look retroactively at which channels were involved and end up with the following result:
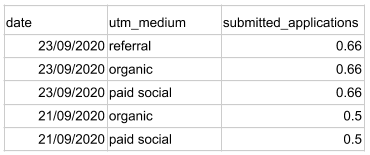
As a result, each conversion is distributed between all the previous journeys, and the timestamp of the conversion is set.
Applying the logic to the whole raw dataset
The logic is very straightforward, now we apply the same idea to the whole data frame, meaning that all conversions will be distributed across all the journeys that a user made before the conversion.
To do so, we’ll set up a loop in a Jupyter notebook. The workflow will be the following:
- Extract the data from your data source into a dataframe
- Execute the loop applying the logic described above to the whole dataframe.
- Load the data to the destination table
We first need to import the required libraries
import pygsheets
import pandas as pd
from oauth2client.service_account
import ServiceAccountCredentials
import gspread
import jsonCode language: JavaScript (javascript)In this step, we extract the data from our raw Google Analytics data source and store it into a pandas dataframe. In the following example, we just pull the data from our Google Sheet, as explained in this tutorial on connecting a Google Sheet to a notebook. You can also extract the data from any database and store it in a pandas dataframe.
#import the json file with the google credentials
with open("google_credentials.json", "r") as f:
google_credentials = json.load(f)
#load the credentials in the right variable
scope = ['https://www.googleapis.com/auth/cloud-platform', 'https://spreadsheets.google.com/feeds']
credentials_gs = ServiceAccountCredentials.from_json_keyfile_dict(google_credentials, scope)
gc = gspread.authorize(credentials_gs)
#pull data from the right google spreadsheet and insert it into a dataframe
spreadsheet_key = 'YOUR_SPREADSHEET_KEY'
book = gc.open_by_key(spreadsheet_key)
worksheet = book.worksheet("GA raw data")
table = worksheet.get_all_values()
ga_raw_data = pd.DataFrame(table[1:], columns=table[0])Code language: PHP (php)Then, we need to get the dataframe into the right format before we integrate it into the loop.
#basic transformation on the dataframe to have the right format
ga_raw_data = ga_raw_data.filter(items=['date', 'user_id', 'journey_id', 'utm_medium', 'submitted_applications'])
ga_raw_data = ga_raw_data.sort_values(by=['date', 'user_id'], ascending=True)
ga_raw_data['submitted_applications'] = ga_raw_data['submitted_applications'].astype(str).astype(int)
ga_raw_data['date'] = pd.to_datetime(ga_raw_data['date'])
ga_raw_data = ga_raw_data.reset_index().drop(columns=['index'])
ga_raw_data.head()Code language: PHP (php)Now comes the most important step, as we’ll loop over all the conversions in the raw dataframe and iteratively create a new dataframe that contains linearly attributed conversions.
#Setting up the empty dataframe that will be filled with the attributed conversions
columns = ['date', 'utm_medium', 'conversions']
attributed_conversion_df = pd.DataFrame(columns=columns)
#looping over all the rows of the raw GA dataframe
for index, row in ga_raw_data.iterrows():
#looking for rows that have at least 1 conversion
if row['submitted_applications'] > 0:
#create a dataframe with the conversion raw and all former sessions of this user
single_conversion_df = ga_raw_data[(ga_raw_data['date'] <= pd.to_datetime(row["date"])) & (ga_raw_data['user_id'] == row["user_id"])]
#sorting by date and number of conversion ascending
single_conversion_df = single_conversion_df.sort_values(by=['date', 'submitted_applications'], ascending=True)
#rank all the sessions in the user history (from the first one to the conversion)
single_conversion_df['occurrences'] = single_conversion_df.groupby('user_id').cumcount() + 1
#set up a variable with the total number of sessions
occurrences = single_conversion_df.loc[(single_conversion_df['submitted_applications'] == row["submitted_applications"]) & (single_conversion_df['date'] == row["date"])& (single_conversion_df['utm_medium'] == row["utm_medium"]), 'occurrences'].iloc[0]
#set up a value that divides the conversion(s) by the number of session
conversion_per_row = single_conversion_df.loc[single_conversion_df['submitted_applications'] == row["submitted_applications"], 'submitted_applications'].iloc[0]/occurrences
#append the linear distributed conversion to each row
single_conversion_df['conversions'] = float(conversion_per_row)
#set the conversion date for each row
single_conversion_df['date'] = single_conversion_df.loc[(single_conversion_df['submitted_applications'] == row["submitted_applications"]) & (single_conversion_df['date'] == row["date"])& (single_conversion_df['utm_medium'] == row["utm_medium"]), 'occurrences'].iloc[0]
#filter the relevant columns for the attributed dataframe
single_conversion_df = single_conversion_df.filter(items=['date', 'utm_medium', 'conversions'])
#append the conversion dataframe to the main dataframe
attributed_conversion_df = attributed_conversion_df.append(single_conversion_df)
attributed_conversion_df.head(50)Code language: PHP (php)Finally, we just have to push the new dataframe to the right destination. In our case, we push it to the same Google Sheet, in another tab.
#authorization
gc = pygsheets.authorize(service_file='google_credentials.json')
#open the google spreadsheet (where 'PY to Gsheet Test' is the name of my sheet)
sh = gc.open("Multi-touchpoint attribution model - Talent Acquisition")
#select the first sheet
wks = sh[1]
#update the first sheet
wks.set_dataframe(attributed_conversion_df,(1,1))Code language: PHP (php)Visualizing and comparing the insights
Now that we have created our new attribution model and have access to a new dataset, let’s compare both models and see if there’s any significant difference. To do so, we can just create a visualisation for the two different datasets:
- Standard last-click attribution
- Multi touchpoint attribution
In our Talent Acquisition example, we created Data Studio charts on top of each of the two different datasets. Feel free to visualise according to your liking!
Here’s the distribution of all conversions among channels, based on the last click:
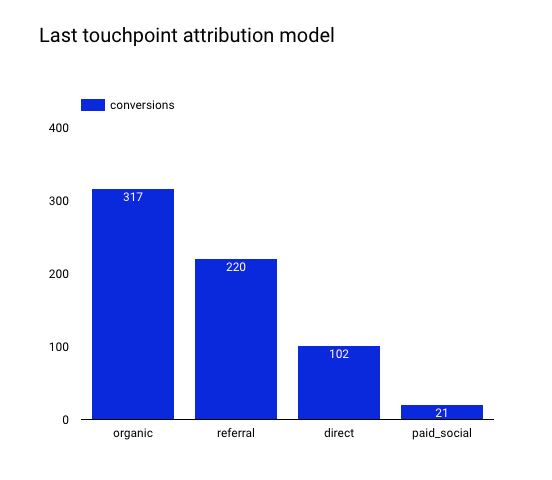
We have a total of 660 conversions that are distributed among four channels. All numbers are integers, as a conversion can only be attributed to one source: the last click source.
Here we’ve distributed the conversions based on the multi-touchpoint attribution model. As you can see, we have the same number of conversions (660). We’ve just distributed all conversions across the different channels that were involved.
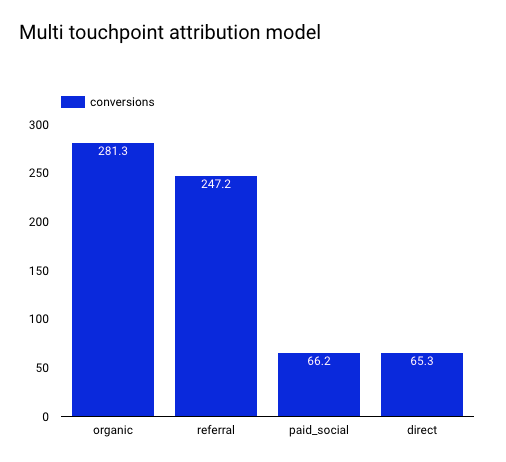
As we can see, the referral and paid_social channels have a higher level of attribution whereas organic and direct channels are lower, compared to the last-touchpoint attribution graph. It is very likely that users have first sessions coming from social media or referring websites but end up applying after they arrive from Google or after typing the website address directly.
This distribution seems to make more sense and gives more weight to impactful channels that were under-represented in the last-click attribution model. Based on these findings, our TA team decided to spend more on paid_social (e.g. LinkedIn) because this source of conversions was underrepresented in the “last click” logic.
Wrap-up
That’s it! With a very simple setup, we were able to create a basic attribution model. It’s worth noting that this is a very simplified version which is already much more accurate than standard Google Analytics reports. But you get the logic and feel free to use this example as a basis to define an advanced attribution model that makes more sense to your business.
To try it out for yourself, see my demo Jupyter notebook with all the code excerpts from this article.
Here some ideas to work on:
- Conversion window
When looping over the previous sessions, it might make sense to set time limits, e.g. only take into account the journeys that happened during the last two weeks. - Weight the sessions based on ranking
We have here a linear attribution model but it might make sense that some sessions are counted as more important than others during the user’s journey, e.g. the first session could have the highest weight when distributing the conversion. - Exclude outliers
One simple thing would be to exclude conversions or sessions that have too many conversions so that you don’t skew the final results. e.g. You could filter out sessions that had more than 10 applications and/or 25 sessions. - Event stream
As said, this example simply executes a linear distribution of all UTM sources. You can do much more with this. For example, you could model the event completions up to the conversions. In the user journey described above, we would know that the user had played podcast abc and read job description xzy before conversion.