By Martin Loetzsch, Jieying Yan, and Selim Nowicki
Pixel-based tracking is dead. In the past, if we wanted to analyze how people interact with our product, we had to rely on tracking code snippets that send data from the web browser to tools such as Google Analytics or Snowplow. However, now that ad blockers and privacy-aware web browsers are increasing in popularity, this has become less of an option (which is actually a good thing). But it also makes it more difficult for us to understand how our product is used and where our visitors come from. Pixel-based tracking makes us ever more blind to many user interactions.
Server-side tracking is the solution to this problem: rather than collecting data from the client (web browser), events are collected on the server side (the code that serves the web site). Server-side tracking restores transparency in marketing sources and product usage, but beyond that, you gain a few other advantages and use cases when you track events on the server side:
- Ground truth: you can establish a real baseline for your other your pixel-based marketing analytics tools.
- Price: it provides a cheaper alternative to Google Analytics Premium / Segment, etc.
- GDPR compliance: you own the data and avoid black boxes.
- Unified user journey: you can combine events from multiple touchpoints.
- Site speed: the front-end loads faster because there are no analytics pixels to slow it down.
- SEO: you can measure how search engines index your site.
There are also a few disadvantages:
- You need to maintain an additional tech infrastructure
- You have to implement features such bot as detection, session construction and bounce rate computation yourself (normally an analytics vendor would handle this).
However, the advantages by far outweigh the additional effort and we found that server-side tracking as surprisingly easy to implement.
A minimal server side tracking setup
The infrastructure for server-side tracking is often perceived as somewhat difficult to build, but in this post, we want to show you that it doesn’t have to be. We will walk you through a minimal infrastructure that we set up for tracking visits to the Project A web site:
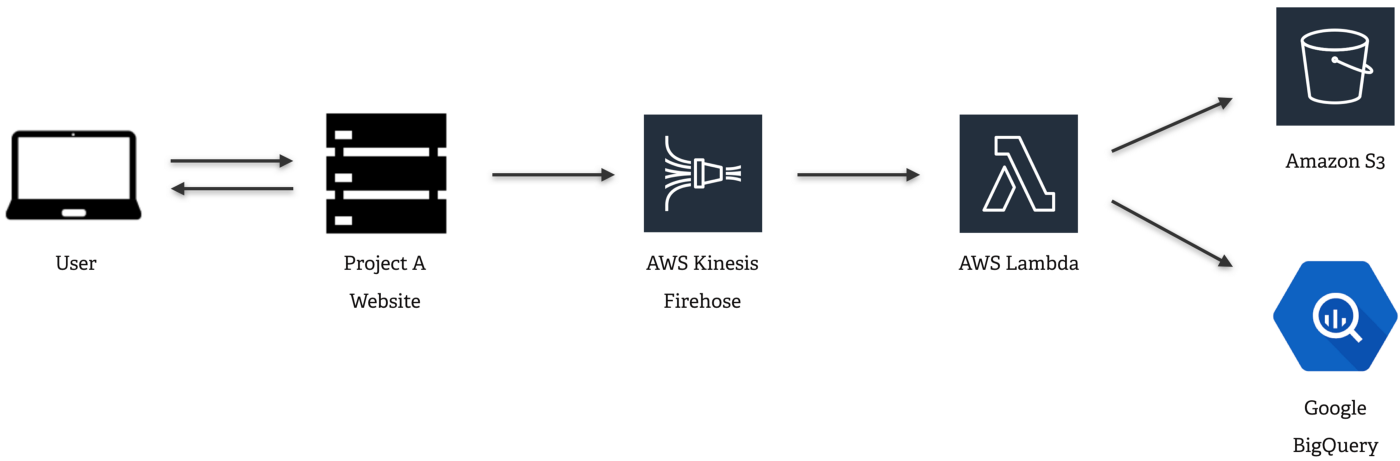
For each page requested by a user:
- The backend of the Project A web site sends an event to an AWS Kinesis Message Queue.
- A few moments later, an AWS Lambda function takes the event out of the queue again, applies some transformations and then it ..
- backs up the data to an AWS S3 cloud storage bucket and
- writes the data to Google BigQuery for easy analysis with SQL queries.
Collecting events on the server side
As with pixel-based tracking, you need to decide what information to actually track. We recommend that you collect everything that the backend knows about the user (independent from current use cases), as well as the context and the content that they consumed.
For example, this is what the Project A website backend collected about a visit that I made to a specific page in our career section:
{
"visitor_id": "10d1fa9c9fd39cff44c88bd551b1ab4dfe92b3da",
"session_id": "9tv1phlqkl5kchajmb9k2j2434",
"timestamp": "2018-12-16T16:03:04+00:00",
"ip": "92.195.48.163",
"url": "https://www.project-a.com/en/career/jobs/data-engineer-data-scientist-m-f-d-4072020002?gh_jid=4082751002&gh_src=9fcd30182&&utm_medium=social&utm_source=linkedin&utm_campaign=buffer",
"host": "www.project-a.com",
"path": [
"en",
"career",
"jobs",
"data-engineer-data-scientist-m-f-d-4072020002"
],
"query": {
"gh_jid": "4082751002",
"gh_src": "9fcd30182",
"utm_medium": "social",
"utm_source": "linkedin",
"utm_campaign": "buffer"
},
"referrer": null,
"language": "en",
"ua": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.110 Safari/537.36"
}
Code language: JSON / JSON with Comments (json)How do you get this information? Well, it really depends on your tech stack. Unfortunately, there’s no one-size-fits-all solution. The good news is that there’s usually already some server-side code that collects this information for tracking and marketing pixels — either directly or through something like Google Tag Manager (GTM). So a good heuristic could be to track everything that you would otherwise put in the data layer of GTM.
The actual code for collecting events and sending them to a queue depends on the programming language and framework of the backend. This how a tracking collector for Kirby (a PHP-based CMS solution) could look like:
<?php
require 'vendor/autoload.php';
// this cookie is set when not present
$cookieName = 'visitor';
// retrieve visitor id from cookie
$visitorId = array_key_exists($cookieName, $_COOKIE) ? $_COOKIE[$cookieName] : null;
if (!$visitorId) {
// visitor cookie not set. Use session id as visitor ID
$visitorId = sha1(uniqid(s::id(), true));
setcookie($cookieName, $visitorId,
time() + (2 * 365 * 24 * 60 * 60), '/',
'project-a.com', false, true);
}
$request = kirby()->request();
// the payload to log
$event = [
'visitor_id' => $visitorId,
'session_id' => s::id(),
'timestamp' => date('c'),
'ip' => $request->__debuginfo()['ip'],
'url' => $request->url(),
'host' => $_SERVER['SERVER_NAME'],
'path' => $request->path()->toArray(),
'query' => $request->query()->toArray(),
'referrer' => visitor::referer(),
'language' => visitor::acceptedLanguageCode(),
'ua' => visitor::userAgent()
];
$firehoseClient = new \Aws\Firehose\FirehoseClient([
// secrets
]);
// asynchronically publish message to firehose delivery stream
$promise = $firehoseClient->putRecordAsync([
'DeliveryStreamName' => 'kinesis-firehose-stream-123',
'Record' => ['Data' => json_encode($event)]
]);
register_shutdown_function(function () use ($promise) {
$promise->wait();
});
Code language: HTML, XML (xml)As you can see, it’s surprisingly few lines of code. The $event dictionary is filled with a visitor ID (derived from a first-party cookie variable), a session ID (provided by the web framework) and other data about the request and the visitor. Once the event object has been built, it is sent to a Kinesis “Firehose” stream using the AWS SDK for Kinesis Firehose.
It’s very important not to increase the page load time for the user when we send the event to the queue. We can achieve this by sending the event asynchronously. So, in the example above, the function call $firehoseClient->putRecordAsync(..) immediately returns, without waiting for the request to finish. After the page is sent to the user, a “shut down handler” waits for the communication with Kinesis to finish.
Event preprocessing and storage
Once the event has been collected in the queue, it needs a little bit of preprocessing (mainly to preserve user privacy) before it is written to permanent storage. This is the preprocessed version of the raw event JSON that we showed previously:
{
"visitor_id": "10d1fa9c9fd39cff44c88bd551b1ab4dfe92b3da",
"session_id": "9tv1phlqkl5kchajmb9k2j2434",
"timestamp": "2019-12-16T16:03:04+00:00",
"url": "https://www.project-a.com/en/career/jobs/data-engineer-data-scientist-m-f-d-4072020002?gh_jid=4082751002&gh_src=9fcd30182&&utm_medium=social&utm_source=linkedin&utm_campaign=buffer",
"host": "www.project-a.com",
"path": [
"en",
"career",
"jobs",
"data-engineer-data-scientist-m-f-d-4072020002"
],
"query": [
{
"param": "gh_jid",
"value": "4082751002"
},
{
"param": "gh_src",
"value": "9fcd30182"
},
{
"param": "utm_medium",
"value": "social"
},
{
"param": "utm_source",
"value": "linkedin"
},
{
"param": "utm_campaign",
"value": "buffer"
}
],
"referrer": null,
"language": "en",
"browser_family": "Chrome",
"browser_version": "70",
"os_family": "Mac OS X",
"os_version": "10",
"device_brand": null,
"device_model": null,
"country_iso_code": "DE",
"country_name": "Germany",
"subdivisions_iso_code": "SN",
"subdivisions_name": "Saxony",
"city_name": "Dresden"
}
Code language: JSON / JSON with Comments (json)In this preprocessed example, we’ve removed the IP address and instead added fields that describe the user’s geolocation such as country, subdivision and city. The “ua” (user agent) field, which contained a detailed string representation of the visitor’s software and hardware, has also been removed. Instead, we’ve split this information into several fields that describe the user’s operating system, device and browser and detect whether the request came from a bot. Finally, we’ve transformed the query parameters of the request into a representation that is easier for BigQuery to process.
In our example, we use an AWS Lambda function to preprocess and store the events. A lambda function is basically a small piece of code that can be automatically triggered to run on each event in the queue:
import base64
import functools
import json
import geoip2.database
from google.cloud import bigquery
from ua_parser import user_agent_parser
@functools.lru_cache(maxsize=None)
def get_geo_db():
return geoip2.database.Reader('./GeoLite2-City_20200307/GeoLite2-City.mmdb')
def extract_geo_data(ip):
"""Does a geo lookup for an IP address"""
response = get_geo_db().city(ip)
return {
'country_iso_code': response.country.iso_code,
'country_name': response.country.name,
'subdivisions_iso_code': response.subdivisions.most_specific.iso_code,
'subdivisions_name': response.subdivisions.most_specific.name,
'city_name': response.city.name
}
def parse_user_agent(user_agent_string):
"""Extracts browser, OS and device information from an user agent"""
result = user_agent_parser.Parse(user_agent_string)
return {
'browser_family': result['user_agent']['family'],
'browser_version': result['user_agent']['major'],
'os_family': result['os']['family'],
'os_version': result['os']['major'],
'device_brand': result['device']['brand'],
'device_model': result['device']['model']
}
def lambda_handler(event, context):
"""Preprocess a raw event in the Kinesis queue, then write it to BigQuery and S3"""
lambda_output_records = []
rows_for_biguery = []
bq_client = bigquery.Client.from_service_account_json('BigQuery-6e433016ee6b.json')
for record in event['records']:
message = json.loads(base64.b64decode(record['data']))
# extract browser, device, os
if message['ua']:
message.update(parse_user_agent(message['ua']))
del message['ua']
# geo lookup for ip address
message.update(extract_geo_data(message['ip']))
del message['ip']
# update get parameters
if message['query']:
message['query'] = [{'param': param, 'value': value}
for param, value in message['query'].items()]
rows_for_biguery.append(message)
lambda_output_records.append({
'recordId': record['recordId'],
'result': 'Ok',
'data': base64.b64encode(json.dumps(message).encode('utf-8')).decode('utf-8')
})
errors = bq_client.insert_rows(
bq_client.get_table(bq_client.dataset('server_side_tracking').table('project_a_website_events')),
rows_for_biguery)
if errors != []:
raise Exception(json.dumps(errors))
return {
"statusCode": 200,
"body": json.dumps('OK'),
"records": lambda_output_records
}
Code language: PHP (php)To perform geo lookup, the extract_geo_data function uses the geoip2library to extract location information for the IP address of the event.
The user agent details are extracted with the parse_user_agent function. This uses the uap-python library, which is a Python wrapper around a large community-maintained list of regular expressions. Bot detection is handled by this library as well. If the user agent field contains the signature of a known bot, then the device_brand field will contain the value spider.
The lambda_handler function above is automatically invoked for each event in the Kinesis queue. It performs geo lookup and device detection and then sends the event to BigQuery using the BigQuery Python client. The event is also written to an S3 bucket but this happens automatically. We’ve configured Amazon Lambda to automatically save the function’s output to S3 each time the lambda function runs.
Note that our decision to use BigQuery and S3 for event storage is rather arbitrary. There are other good options for storing events such as Google Cloud Storage and Azure Blob Storage and Snowflake. And of course you an also continue to use your existing analytics tools. You can send events from the backend to Google Analytics (via their Measurement Protocol), to Mixpanel, Segment, and so on.
Querying data
Once the data is in BigQuery, you can write SQL queries like the one below:
WITH
relevant_session AS (
SELECT
session_id,
timestamp
FROM
`pav-analytics.server_side_tracking.project_a_website_events`
WHERE
REGEXP_CONTAINS(url, '(?i)jobs/data-engineer-data-scientist')
AND device_brand != 'Spider')
SELECT
COUNT(*) AS n,
url
FROM
`pav-analytics.server_side_tracking.project_a_website_events` event,
relevant_session
WHERE
event.session_id = relevant_session.session_id
AND event.timestamp < relevant_session.timestamp
AND NOT (ARRAY_LENGTH(path) > 2
AND path[OFFSET(1)] IN ('karriere', 'career'))
GROUP BY
url
ORDER BY
n DESC
LIMIT
20
Code language: JavaScript (javascript)It lists the other URLs from our website that visitors viewed before they saw the job ad for our data engineer / data scientist position:
cat text/bigquery-example-query.sql | bq query --nouse_legacy_sql
Waiting on bqjob_r1213acb52d17011a_0000016cfc7967d0_1 ... (0s) Current status: DONE
+-----+------------------------------------------------------------------------------+
| n | url |
+-----+------------------------------------------------------------------------------+
| 109 | https://www.project-a.com/de/offline |
| 108 | https://www.project-a.com/en/offline |
| 93 | https://www.project-a.com/en |
| 36 | https://www.project-a.com/ |
| 34 | https://www.project-a.com/en/about-us/who-we-are |
| 29 | https://www.project-a.com/de |
| 21 | https://www.project-a.com/en/portfolio |
| 14 | https://www.project-a.com/en/about-us/expertise |
| 13 | https://www.project-a.com/en/media/press-releases |
| 9 | https://www.project-a.com/en/contact |
| 9 | https://www.project-a.com/career/recommend-friends |
| 7 | https://www.project-a.com/en/media/press-releases?offset=6 |
| 7 | https://www.project-a.com/de/ueber-uns/wer-wir-sind |
| 6 | https://www.project-a.com/en/media/press-releases?offset=138 |
| 6 | https://www.project-a.com/en/media/video |
| 6 | https://www.project-a.com/en/portfolio/natue |
| 6 | https://www.project-a.com/jobs/4082751002?gh_jid=4082751002&gh_src=bc4eeadd2 |
| 6 | https://www.project-a.com/en/portfolio/trendtours |
| 5 | https://www.project-a.com/en/portfolio/lampenwelt |
| 5 | https://www.project-a.com/en/portfolio/spryker-systems |
+-----+------------------------------------------------------------------------------+
Code language: JavaScript (javascript)That’s probably not the most insightful analysis, but you get the idea.
Which brings us to the end of this post. We hope that we were able to convince you that nowadays, it’s quite easy to set up a server-side tracking infrastructure without doing too big of a tech investment. The additional complexity compared to pixel-based tracking solutions lies in the definition of events, session modelling, and device and bot detection. Keep in mind that the above combination of Kinesis, Lambda functions, BigQuery and S3 is only one possible way of tackling the problem, but it’s a combination that we can recommend.