By Tobi Wole
When I started working as a data engineer, I often wondered how to deal with a situation where data stored in a database changes over time. For example, what do I do when customers update their personal information and effectively alter the entry in a specific database column? I would ask questions like:
- How do I properly deal with this new record reflected in the data warehouse?
- How do I retain the historical references of a given attribute?
Thankfully, there are several typical ways to deal with these scenarios in the business world.
Scenario: Track sales locations
Imagine you work on the Data and Analytics team of an e-commerce site that operates in two cities, London and Berlin. Each city has a sales manager, and the top-performing person gets a monthly bonus. To decide who gets the bonus, we aggregate the performance in a report we generate at the end of the following month.
We need to write the SQL query to retrieve the information about our orders and help us generate the monthly report:
SELECT o.order_date, c.customer_city, c.customer_id, o.order_id
FROM `orders` o
LEFT JOIN `customer_dim` c
ON o.customer_id = c.customer_idCode language: JavaScript (javascript)This snippet pulls the relevant data from the columns in our orders table (note the first two rows, listing the cities of customers A100 and B200):
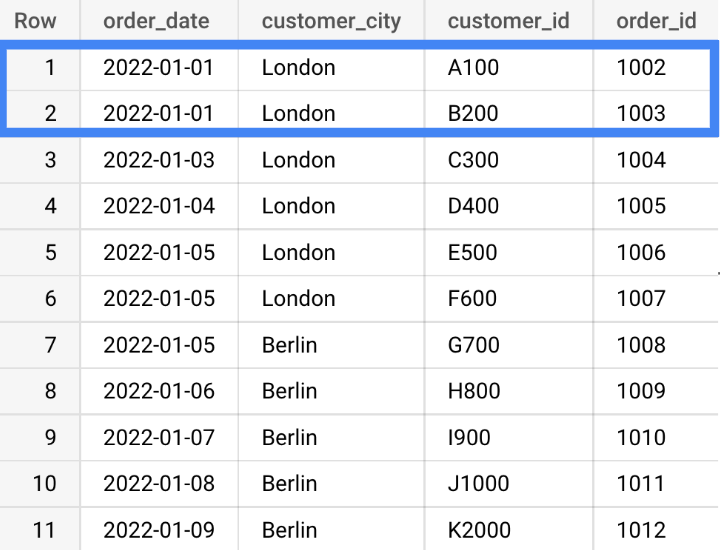
The official report isn’t due until the end of February, but we wanted to get an early glimpse of the results, so we run the following query at the end of January:
SELECT order_date, customer_city, COUNT(order_id) AS total_orders
FROM `orders`
WHERE DATE_TRUNC(order_date, month) = ‘2022–01–01’
GROUP BY 1Code language: JavaScript (javascript)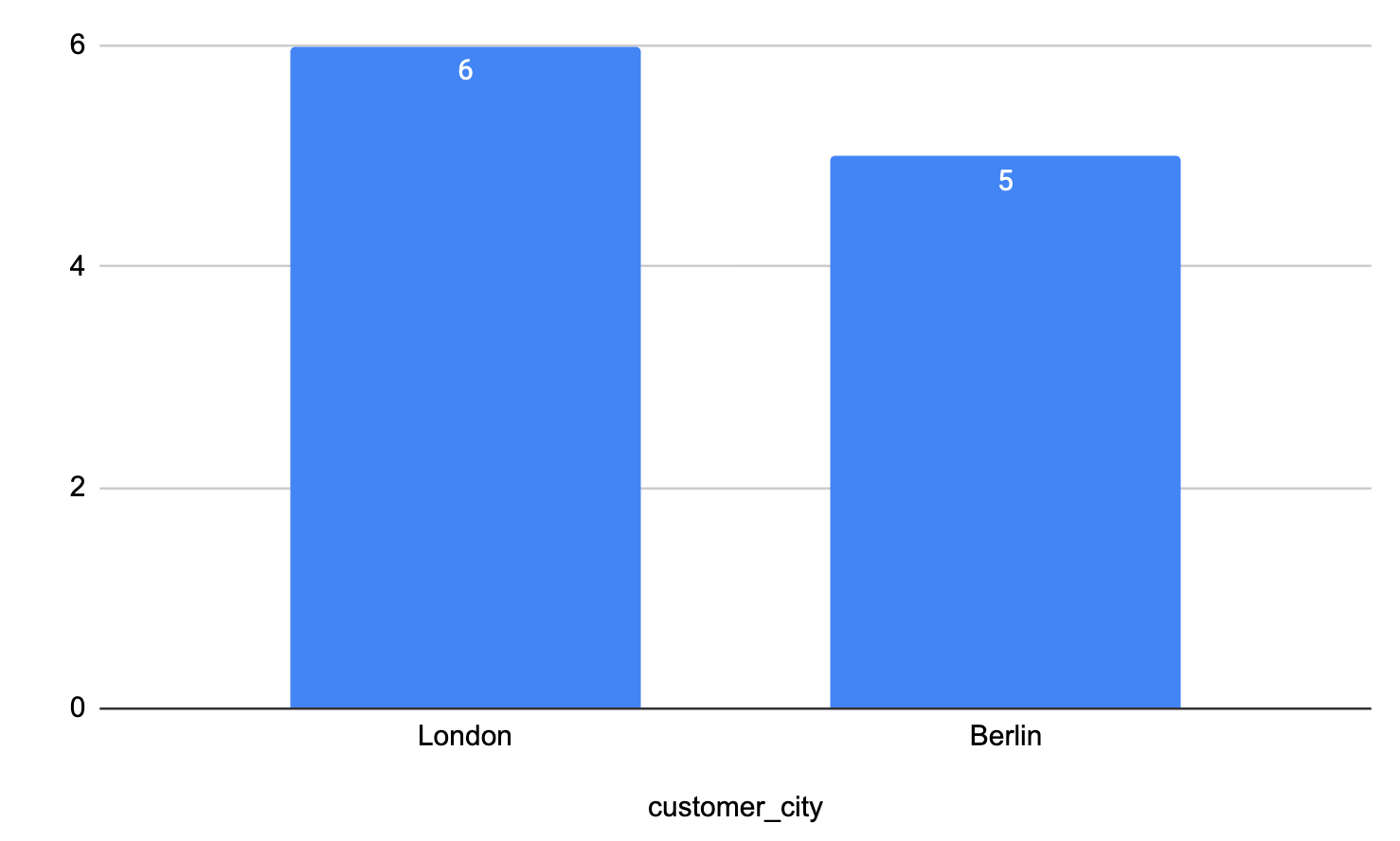
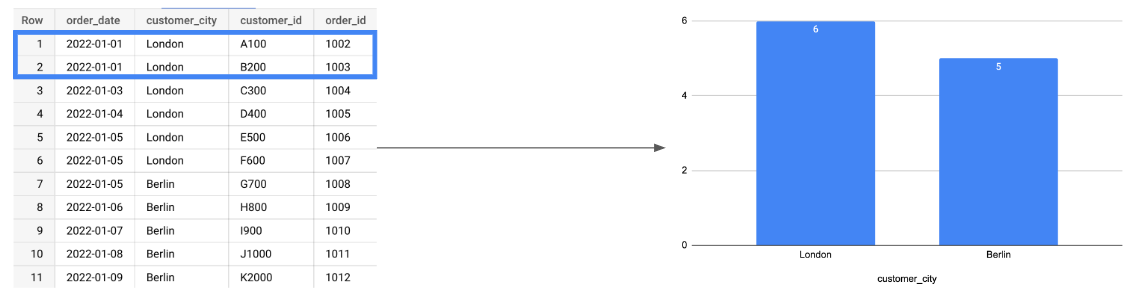
It was a close call, but in January, the London Sales Manager won by one extra order. She’s excited and can’t wait to get her bonus.
Meanwhile, sometime in February, customers A100 and B200 moved to Berlin to start a new life. They update their new address in their online profile, so now our orders table and subsequent January report look like this:
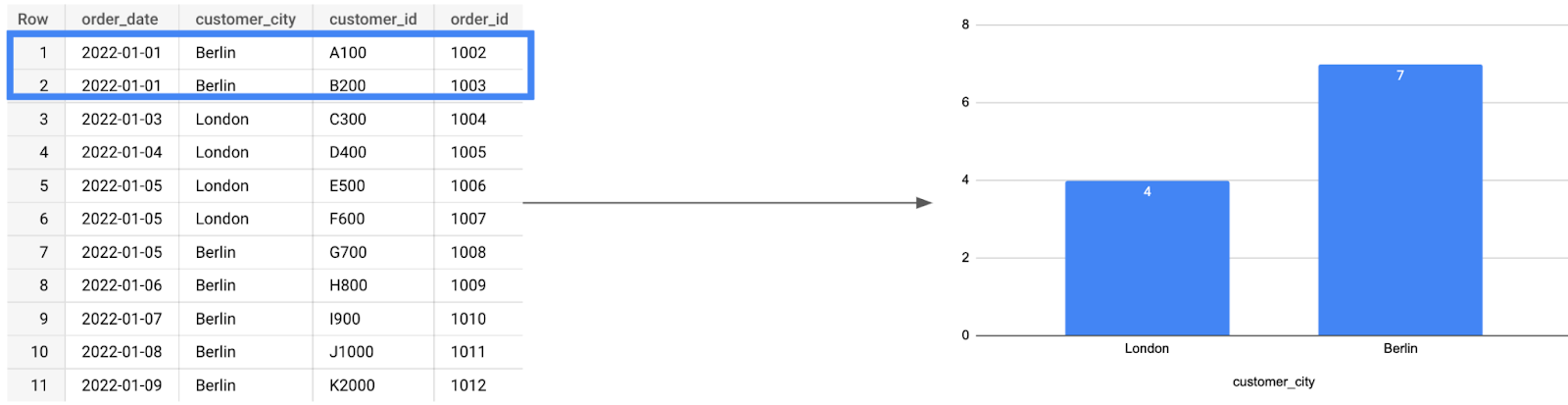
As you can see, the latest report is a false representation of the data as it was back in January (when the sales were actually made).
This isn’t just a problem for the Sales team (let’s hope the London Sales Manager had no plans for her bonus); it also means that other stakeholders in the company wouldn’t know where the customer made their original order. Finally, this could be a bit embarrassing for the Data & Analytics crew tasked with collecting such critical information. Talk about the butterfly effect.
The Solution: Slowly Changing Dimensions (SCD)
Fortunately, we can solve everyone’s problems by integrating a concept called Slowly Changing Dimensions (SCD) into our data warehouse.
There are several types of SCD techniques, but we’ll focus on Type 2 as it’s one of the most common approaches.
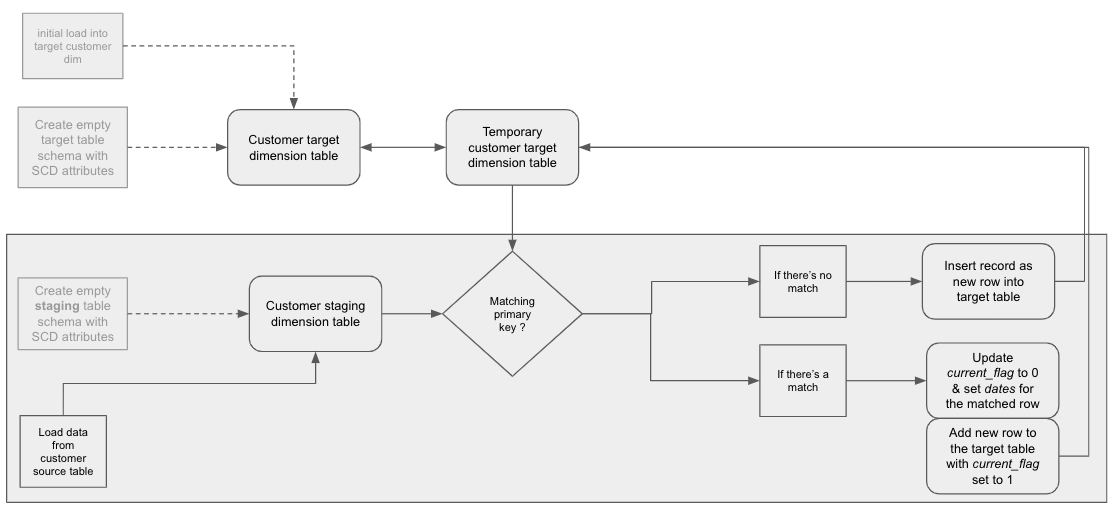
The folks at Amazon Web Services (AWS) came up with a brilliant flowchart, which lists the steps one should consider when developing SCD Type 2. Above is our slightly modified version, adapted to fit the Google BigQuery data warehouse we’re referencing in our tutorial.
Starting from left to right, with the customer table at the top serving as the output, you would run the greyed-out steps only once. The rest are applied on every subsequent run of your Extract, Transform, Load (ETL) pipeline.
We’ll use this chart as our guide throughout the rest of this tutorial.
Let’s get going.
Tutorial: Implementing SCD Type 2
While not a deal-breaker, we assume readers have some previous experience with SQL and data modelling. Not there yet? You’re most welcome to follow along anyway!
Prerequisites:
- A Google BigQuery account
- A sample project
- SQL editor of your choice
Create a dimension schema with SCD attributes
We’ll need to modify our original customer dimension table (left), which currently contains only three fields, and add the SCD attributes that would help us track changes over time:
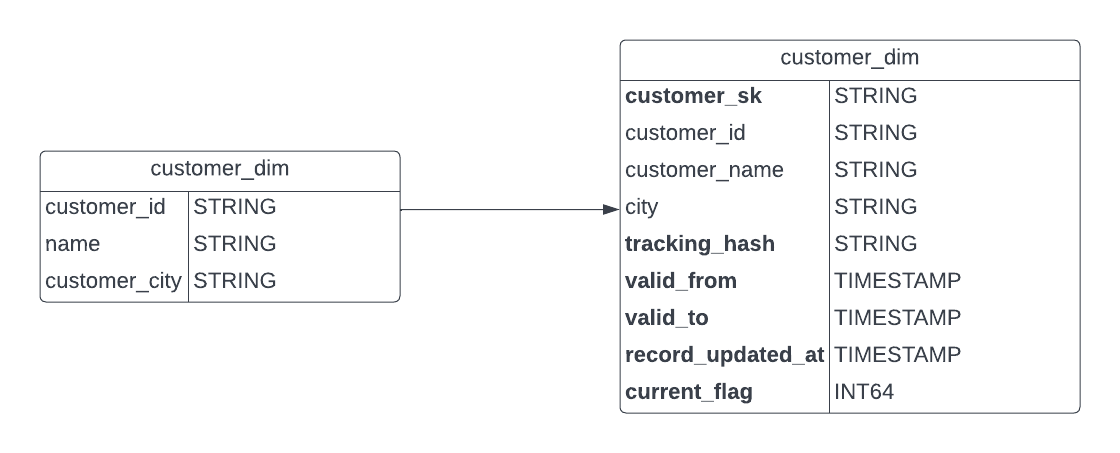
Here is a description of the new SCD attributes we will be adding:
- customer_sk: An artificial primary key (aka, a surrogate key) that is a sequentially assigned integer or a uniquely generated value for every Type 2 change in our dimension. This surrogate key will be the unique identifier of each row in the table.
- customer_id: Same as the original table.
- name: Same as the original table.
- customer_city: Same as the original table.
- tracking_hash: This gives us an effective way to track changes of specific fields in a given customer_dim table. This way, we don’t need to keep track of multiple columns in the table — a single column indicates when any row changes.
- valid_from: Specifies the date from which the record is valid.
- valid_to: Specifies the last date before the record changed.
- record_updated_at: Specifies the date a record was last updated in the table.
- current_flag: Specifies if the record is the current/most recent entry.
Here is the code to create the customer dimension schema:
CREATE OR REPLACE TABLE `customer_dim` (
customer_sk STRING,
customer_id STRING,
name STRING,
customer_city STRING,
tracking_hash STRING,
valid_from TIMESTAMP,
valid_to TIMESTAMP,
record_updated_at TIMESTAMP,
current_flag INT64
)Code language: JavaScript (javascript)Initial load
The next step is to load the initial data into the table, adding the default SCD values and modeled attributes from the raw_customer source table.
You should run the following SQL snippet only once:
INSERT INTO `customer_dim`
SELECT
GENERATE_UUID() AS customer_sk,
customer_id,
name,
customer_city,
TO_HEX(MD5(CONCAT(name, customer_city))) AS tracking_hash, # only the 'tracking_hash' column will be looked up to detect a change in the record, so we don't have to monitor multiple columns ---
CAST('1970-01-01' AS TIMESTAMP) AS valid_from,
CAST('2999-12-31' AS TIMESTAMP) AS valid_to,
CURRENT_TIMESTAMP AS record_updated_at,
1 AS current_flag
FROM
`raw_customer`Code language: PHP (php)- GENERATE_UUID(): This function is specific to BigQuery. It creates a unique identifier that serves as the surrogate key of each row in the query result during run-time. You could also use the MD5 hash function to run a hash on all columns in your table and generate a 16 bytes key.
- Only the tracking_hash column will be used to detect a changed record. That way, we don’t have to keep track of multiple columns within the same table. The
tracking_hashcolumn in the code snippet above concatenates two columns, name and customer_city. In our example, we need to track only thecustomer_citycolumn, but I wanted to show how we would approach multiple columns. Feel free to remove theCONCAT()function and replace it with the customer_city column alone. Your code on line 16 should then look like this:
TO_HEX(MD5(customer_city)) AS tracking_hash,
- The
MD5function computes the hash of the input using the MD5 algorithm. The input can be either STRING or BYTES. - The
TO_HEXfunction converts the sequence of bytes returned by theMD5algorithm into a hexadecimal string, ensuring the hash outputs as a string.
Use a proxy table
Before we continue, we should create a proxy customer_dim table, e.g., the customer_dim_next.
The proxy table is an exact copy of the customer_dim table that prevents any manipulations of the primary customer table. This precaution guarantees that our primary table remains intact if a failure occurs. Once all changes have successfully passed, we can load the content of customer_dim_next directly into customer_dim.
CREATE OR REPLACE TABLE customer_dim_next
AS SELECT * FROM customer_dim;Code language: PHP (php)Subsequent loads
For subsequent loads, we create a staging table called customer_dim_staging that retrieves data from the raw_customersource table and compares it to the target customer_dim table we’ve just created.
CREATE OR REPLACE TABLE `customer_dim_staging` (
customer_id STRING,
name STRING,
customer_city STRING,
tracking_hash STRING,
valid_from TIMESTAMP,
new_record INT64,
changed_record INT64
)Code language: JavaScript (javascript)The schema of the staging table is very similar to the customer_dim table but includes two new flag columns that help us identify what sort of change occurred in the source table. There isn’t any surrogate key in this table.
- The
new_recordflag indicates a new record that doesn’t exist in the target table and needs to be inserted. - The
changed_recordflag tells us that we need to update the relevant record in the target table.
After you’ve created the schema for the staging table, you would run this to track changes in the raw_customer source table:
# Truncate the last staging table and add fresh data from the source table
TRUNCATE TABLE `customer_dim_staging`;
INSERT INTO `customer_dim_staging`
WITH staging AS (
SELECT
customer_id AS customer_id_staging ,
name AS name_staging,
customer_city AS city_staging,
TO_HEX(MD5(customer_city)) AS tracking_hash_staging,
CURRENT_TIMESTAMP() AS valid_from_staging # If your database has a timestamp attribute that indicates when the data is loaded, use it instead.
FROM
`raw_customer`
)
SELECT
s.*,
CASE
WHEN c.customer_id IS NULL THEN 1
ELSE 0
END AS new_record,
CASE
WHEN c.customer_id IS NOT NULL
AND s.tracking_hash_staging != c.tracking_hash THEN 1
ELSE 0
END AS changed_record
FROM
staging s
LEFT JOIN `customer_dim_next` c
ON s.customer_id_staging = c.customer_idCode language: PHP (php)UPSERT (UPDATE and INSERT)
This section is the core of our operation, where we perform three tasks:
- First, we track changes:
- When we identify a Type 2 change in any record, we update the SCD columns for that record with a new
valid_todate. - We set the
current_flagto 0 since it’s no longer the latest version. - We set the
record_updated_atcolumn to the current timestamp.
2. Next, we insert a new record with the most recent data points into the customer_dim table. We do the same if a new record is identified in the source table.
3. Lastly, we update all other columns that aren’t tracked as SCD Type 2 but might have changed.
### 1. UPDATE TYPE 2 COLUMN CHANGES (INLINE) ###
# Update records in the target dim table when 'changed_record' = 1, meaning a column in the dim table has changed #
UPDATE `customer_dim_next`
SET valid_to = valid_from_staging,
current_flag = 0,
record_updated_at = CURRENT_TIMESTAMP()
FROM `customer_dim_staging`
WHERE customer_id = customer_id_staging
AND FORMAT_DATE('%Y-%m-%d',valid_to) = '2999-12-31'
AND changed_record = 1;
### 2. ADD NEW RECORDS AND UPDATED TYPE 2 COLUMNS (NEW ROWS) TO THE TARGET DIM TABLE ###
# Now, we need to add the records that changed from the staging data as well a new data that never existed in the data warehouse #
INSERT INTO `customer_dim_next`
(customer_sk,customer_id,name,customer_city,tracking_hash,valid_from,
valid_to,record_updated_at,current_flag)
SELECT
GENERATE_UUID() AS customer_sk_staging,
customer_id_staging,
name_staging,
customer_city_staging,
tracking_hash_staging,
valid_from_staging AS valid_from,
CAST('2999-12-31' AS TIMESTAMP) AS valid_to_staging,
CURRENT_TIMESTAMP() AS record_updated_at_staging,
1 AS current_flag
FROM
`customer_dim_staging`
WHERE
changed_record = 1 OR new_record = 1;
### 3. UPDATE ROWS THAT MAY OR MAY NOT HAVE CHANGED AND ARE NOT TRACKED AS SCD TYPE 2 ###
#update type 1 current active records for non-tracking attributes #
UPDATE `customer_dim_next`
SET customer_id = customer_id_staging,
name = name_staging,
record_updated_at = CURRENT_TIMESTAMP()
FROM
`customer_dim_staging`
WHERE
customer_id = customer_id_staging
AND FORMAT_DATE('%Y-%m-%d',validTo) = '2999-12-31'
AND changed_record = 0 AND new_record = 0;
### end merge operation ###Code language: PHP (php)Create the final table
Assuming all went well, the final step in your ETL pipeline is to replace the customer_dim table with the content from our proxy table, customer_dim_next.
CREATE OR REPLACE TABLE customer_dim AS (
SELECT * FROM customer_dim_next;)Code language: PHP (php)Now, with all changes tracked within the same table, our SCD Type 2 table should look like this:

customer_dim table with SCD Type 2 attributesRecreating the orders dataset
After successfully implementing SCD Type 2, we need an updated orders table, which includes our newly-created surrogate key, the current_flag column, or the valid_from and valid_to columns.
Let’s recreate our orders table (see figure 1 above) and modify our query by adding the valid_from and valid_to date columns to the WHERE clause, like so:
SELECT
o.order_date,
c.customer_city,
c.customer_id,
o.order_id
FROM `orders` o
LEFT JOIN `customer_dim` c
ON o.customer_id = c.customer_id
WHERE o.order_date BETWEEN valid_from AND valid_to
AND DATE_TRUNC(order_date, month) = ‘2022–01–01’Code language: JavaScript (javascript)Now, whenever we query our orders table, the customer_city column should always match the city that was valid when an order was placed:
I hope this tutorial will help you implement and improve your data warehousing strategy.
Feel free to share your thoughts in the comments below, and check out my previous articles.