By Merlin carter
Contributing Editors: Zoltan Kincses, Alencar Souza
We were helping a new company in our portfolio, and their AWS bill was too high for the size of their business (so technically, it wasn’t our bill).
We helped this company to reduce its monthly AWS bill from around $2,550 (before tax) to around $773 per month.
We did it by moving their services from containers (in AWS Fargate) to functions (in AWS Lambda).
If you work for a startup and are responsible for infrastructure costs, you might be able to make similar cost reductions. But I don’t want to waste your time with an inapplicable use case. There were some very specific factors that contributed to our success. Here’s the list:
- The growth phase of the company and how quickly they expected to scale (slow and steady growth)
- The performance requirements of the application (not especially high)
- The complexity of the service architecture (very simple worker microservices )
- The effort required to refactor the code (we used PHP, which is well-supported)
These factors all influenced our decision to use FaaS (Functions as a Service) with AWS Lambda rather than “CaaS” (Containers-as-a-Service) with Fargate.
If these factors sound interesting to you, then read on because I’ll explain them in more detail. In a companion article, I also go into more of the technical details about the project and how we had to adapt it for Lambda.
Factors we considered when going choosing Lambda over Fargate
Here, I’ll be comparing two of Amazon’s serverless products (Fargate and Lambda), but these factors generally apply to other vendors as well (i.e. Google’s Kubernetes Engine vs Cloud Functions or Azure’s Kubernetes service vs Azure Functions).
1. The growth phase of the company

Why is this important? Because it will influence the load that your application is expected to handle in the near future. Some startups scale exponentially and quickly outgrow the cheaper solutions that host their platform infrastructure.
Also, FaaS can quickly get more expensive than CaaS at a certain scale. To learn more about this effect, check out this thorough analysis of the Economics of Serverless.
Luckily, this wasn’t a concern for our project.

The project involved a relatively small German e-commerce company. Most of their products are fairly large and require assembly. Here are a few stats to give you an idea of their scale:
- 85 employees
- Roughly €71 million per year in revenue.
- 60k daily visitors during the peak season.
- Up to 300 sales orders per day during the peak season.
They sold a lot of items that were over €1,000, so customers would take their time before deciding to purchase. They weren’t planning to acquire anyone or break into new markets any time soon.
We expected a slow and steady growth trajectory. This meant that their shopfront was unlikely to experience a dramatic spike in load. We could afford to be frugal when sizing the performance requirements for the backend infrastructure.
Performance requirements

We weren’t expecting a steady and continuous load, but rather intermittent bursts of requests. If you need things to be consistently fast and reliable, you’re likely better off with Fargate.
For example, Fargate is probably better if you’re hosting a web application that needs to constantly return results in a required timeframe. You can host a full web application in a Lambda function, but you have to worry about stopping the function from going “cold” (shutting down).
For us, this wasn’t a problem. We were running event-driven workers rather than whole web applications (for the most part).
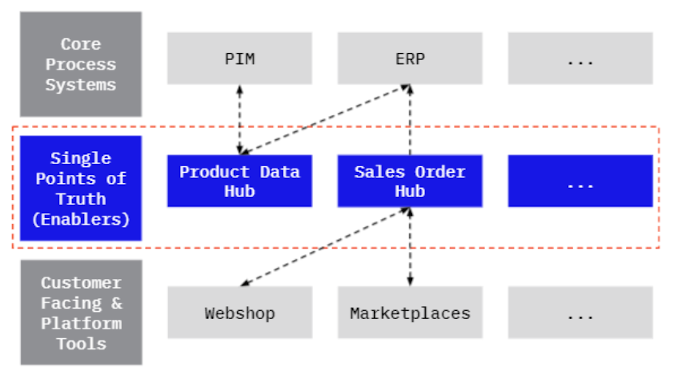
We were building a new back end that was based on several data hubs. We were using data hubs to orchestrate data exchange between the different constituent systems.
Each worker was in charge of exchanging data between the data hub and a satellite system. If you’re interested in more technical details about how this data hub worked, see the companion article. For now, the main points to note here are:
- The services were background workers rather than RESTful endpoints
The customer-facing components of the shop didn’t depend on the services to return any kind of response.
New data is transmitted from the shopfront to the data hub in the background. The data hub polls the shop for new sales orders, but this has no bearing on the customer’s ability to place orders.
This means that we could afford to be more conservative with the resources allocated to each serverless function, which thus kept the price down. - The extra latency caused by “cold starts” was not a big concern
When a Lambda function hasn’t been used for 10mins, it goes “cold”, meaning that its system resources are automatically freed up. When a “cold” function is called again, the system needs some extra time to provision the resources again.
We weren’t concerned about this problem because the processes were running in the background. There was one exception: a basic internal front end for administering business entities (stored as JSON). This front end runs as a full web application in a Lambda function — so it’s sometimes slow for internal users. However, they only use this frontend sporadically, so the delays are acceptable.
The complexity of the service architecture
If you have a huge tangle of services that are tightly coupled, it’s probably not worth the effort of reproducing that complexity in Lambda. You’ll just end up with an interdependent web of serverless functions that will be hamstrung by the “cold start” problem. AWS Lambda is generally better for simpler service architectures.
Our project involved a loosely coupled “hub and spoke” back-end application.
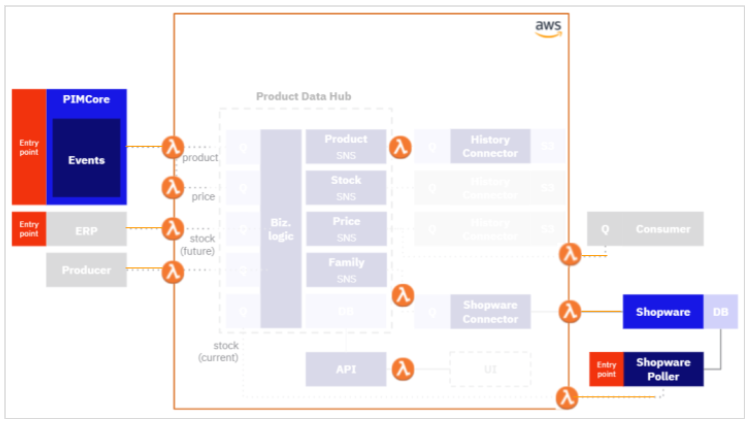
The backend was made up of simple microservices. Typically, the job of each microservice was to take an input message, serialize the data and write it to the data hub. Then, it would publish an output message to broadcast that new data was added to the data hub.
As someone on Hacker News once said. Serverless works best when you “…architect your app from the ground up for serverless by designing single-responsibility microservices that run in separate lambdas…”.
Indeed our architecture already matched this description, so it didn’t take much work to move the application to Lambda functions.
The level of language support and refactoring required

If you search online for “best serverless languages,” you’ll find a lot of articles that benchmark cold start speeds and vendor support. Javascript and Node.js are often contenders for the top spot, but there’s support for many popular programming languages. Nevertheless, the support varies a lot depending on the cloud vendor. AWS Lambda natively supports Java, Go, PowerShell, Node.js, C#, Python, and Ruby but provides a custom Runtime API for other languages. If your application is in a language with no native support, you might have to do more refactoring to get it to work.
Our project was a PHP application that used a third-party custom runtime layer

Yes, PHP doesn’t usually make the list of the 5 best serverless languages, but it’s still the most popular server-side language on the web.
AWS Lambda doesn’t support it natively, but there’s great third-party support. We used the Bref Framework, which provides the required runtimes to run PHP on Lambda. Bref also works seamlessly with The Serverless Framework, which makes it easy to deploy Lambda functions.
If we had attempted this move a few years ago (before Bref was released), the refactoring effort might have been more expensive.
The Takeaway
Serverless architectures are highly scalable, but they aren’t always cheaper. And some serverless solutions will also cost you more than others. In the AWS ecosystem, Fargate is touted as an easy-to-use “serverless” solution. Yet its reliance on containers can still make it the more expensive choice for simple applications.
Unfortunately, there’s no simple formula for deciding when to host an application in ECS with Fargate and when to use AWS Lambda functions. However, I hope that the previous list of factors serves as a useful reference.
If you’re also wondering if Fargate is the best choice for your application, check out my technical breakdown of the project.
There, I go into details such as:
- Exactly why AWS Fargate was more expensive than AWS Lambda (costly NAT Gateway traffic and complexity)
- Everything that we need to change when moving from Fargate to Lambda (SQS queues, database migrations, monitoring, etc…)
- The final results we achieved (cost reduction, new architecture)