By Merlin carter
Contributing Editors: Zoltan Kincses, Alencar Souza
In a previous article, I mentioned that we helped a portfolio company reduce its monthly AWS bill from around $2,200 (before tax) to around $773 per month. Here I’m going to provide more detail on how we did it.
Just to recap, the aim of the preceding article was to explain the main factors that made it an easy win to move from AWS Fargate to AWS Lambda. These factors are worth repeating here before we continue with the details.
The factors were as follows:
- The growth phase of the company and how quickly they expected to scale (slow and steady growth)
- The performance requirements of the application (not especially high)
- The complexity of the service architecture (very simple worker microservices )
- The effort required to refactor the code (we used PHP, which is well-supported)
To expand on the last three factors, I’ll explain our technical use case and why we moved.
Let’s start with the latter.
The company wasn’t happy with how much Fargate costed
AWS Fargate is supposed to be a more user-friendly alternative to running pure ECS or EKS. However, it was still too complex for our small back-end data application.
There were 13 main services that mediated between the producing and consuming systems. Originally, we had placed these services in worker containers. We then used Fargate to automatically provision the required number of worker containers. These workers were deployed to dev, staging, and production clusters. This is a pretty standard setup that we use for many of our projects.
But we had to rethink this tactic when the customer saw their first monthly AWS invoice: it came in at around $2,150 before tax. For a larger company, this amount might seem trivial. But it’s intimidating for a small startup that’s not used to spending so much on IT infrastructure.
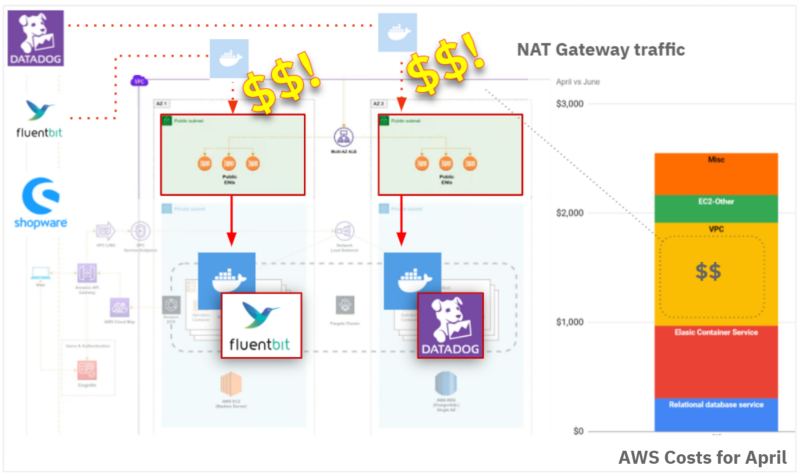
Our application ran in a Virtual Private Cloud (VPC). To ensure that our services were inaccessible from the internet, all traffic to and from the wider internet needed to go through a NAT Gateway. Traffic through the NAT Gateway is charged per hour and per gigabyte.
Some services pulled a large volume of data through the NAT Gateway. Primarily, these were Fluent Bit and the Datadog agent. These services were running in a private subnet. Each time the containers were built, AWS Fargate needed to pull the base images from external registries outside of the virtual private cloud.
You’re might be wondering: “Why doesn’t Fargate cache these images like Kubernetes does?”. Good question. I found a pull request to incorporate image caching (that’s been open since January 2020). The PR’s original author notes, “In all honesty, I feel like I’m being ripped off”.
We could certainly relate to this feeling. Most of our AWS costs were caused by Docker images being pulled through the NAT gateway.
Fargate was too complex for our use case
High AWS costs weren’t the only factor, however. As I mentioned previously, the project had a very simple microservice-based architecture, but we were using a complex system to manage it. Yes, Fargate is nowhere near as complex as managing ECS directly. However, we know that we eventually needed to hand the infrastructure over to the startup’s core team.
In this case, the main person responsible would be an all-rounder — a full-stack engineer with basic DevOps knowledge. He needed a deployment infrastructure that matched the simplicity of the application.
To understand how simple it was, let’s briefly look at the details of the application.
Data hubs with simple connector services
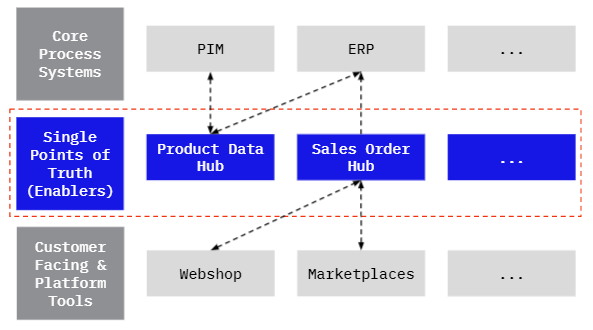
We recommended that this company use data hubs as a way of exchanging data between different systems. This wasn’t happening previously. Data about common business entities (sales orders, product entries, etc.) were duplicated and siloed in the system where the data was created (for example, the Shopware database or an Excel spreadsheet).
This is a shame because, typically, multiple systems are interested in these kinds of entities. Such systems could include a Product Information Management (PIM) system or an Enterprise Resource Planning (ERP) system.
Data hubs give other systems easy access to common business data
By implementing centralized data hubs, we made it easier for systems to share data. Data hubs also make it simpler to integrate new systems that might need to consume this data in the future.
For example, in the previous diagram can see that the product data hub is the single source of truth about product information. Instead of connecting to the PIM directly, other systems like the ERP get their product data from the data hub.
Each service allowed an external system to communicate with the data hub
Let’s take a close look at the architecture of the Product data hub. The following diagram illustrates where these services are involved in the product data hub’s architecture.
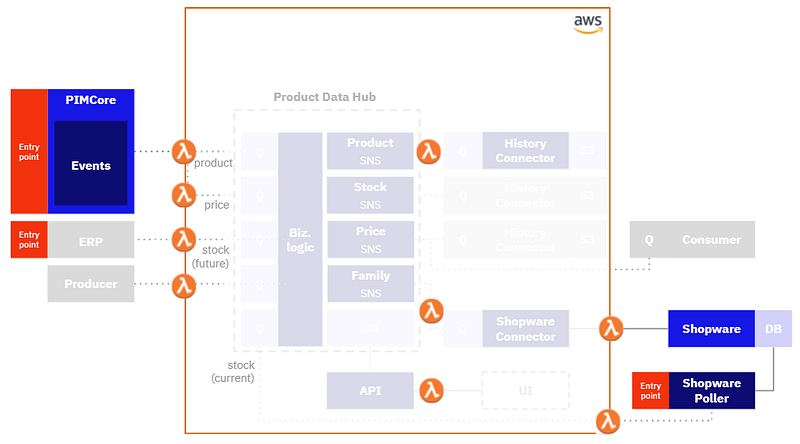
Reading from SQS and broadcasting to SNS
In the original architecture, the services were running as PHP applications in Docker containers. These services subscribed to messages in a queue (AWS SQS) and ran some business logic when a new message arrived. After the process had been completed, the result was broadcast to an SNS topic that other systems subscribed to.
These interactions were managed by the Messenger component of the Symfony framework. The Messenger consumer process is designed to be running the whole time so it can pull messages from the queue.
Why we used SQS and SNS
SQS is useful for messages that have one intended recipient, such as the PIM connector Lambda function. An SQS message can only be consumed once. After the PIM connector is triggered, it reads the message, serializes the payload to the product data hub, and the message is then removed from the queue. This is fine — the data hub is the source of truth, so we don’t want anything else consuming the message.
However, we do want multiple systems to get notifications. To send messages that can be read multiple times, we use SNS. Once the PIM connector records new product data, it emits an event to broadcast that new data is available. This event is sent to an SNS topic, where any other service can subscribe to that topic. When a “new product data” event is detected, a subscribing service can run some downstream business logic. One example of such a service is our “history connector”, which records a log of all product data updates to an AWS S3 bucket. Another example is the Shopware connector which updates the product data in the shop database.
Fargate’s task definitions and security admin were overkill
Containers are configured as part of a “task” (i.e. service) where you while specifying the vCPU and memory required for the containers. You also need to revise the task definition for each deployment. This configuration can be challenging and confusing for novice users. Additionally, each task runs in a private subnet, so you have to deal with complex permissions and security groups if you want the containers to communicate with systems outside of the private cloud. This all requires some degree of DevOps expertise to set up, but our application really wasn’t that complicated. We wanted to make the deployment and administration easy enough for any developer to manage.
Changes required to move to Lambda functions
Moving our services from containers to serverless functions only required a little bit of refactoring. To help you understand what we needed to change, I’ll briefly go into more technical detail about how the services worked.
Figuring out how much memory a Lambda function needs
When thinking about resource requirements, it is slightly different from Fargate to Lambda.
- With ECS and Fargate, you choose the vCPU and memory that you need for each service.
You’re charged per second for the consumption of these resources. - With AWS Lambda, you only select the amount of memory each function needs — vCPU is automatically adjusted depending on the memory requirements.
You’re charged per second for the resource consumption and for the number of times you invoke each function.
We used the AWS Lambda pricing calculator to estimate the cost.
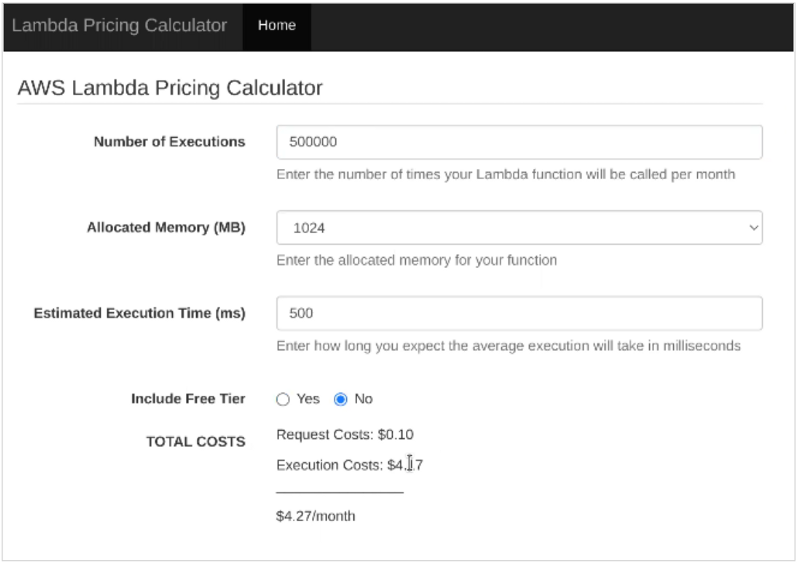
Working out the cost is quite simple:
- We used our existing monitoring data to estimate the number of executions and execution time (the memory requirements were slightly different for each service).
- There was a bit of a gut feeling involved in working out the absolute minimum we could allocate to each service.
- If you want to be more scientific about it, there’s also an AWS Lambda Power Tuning tool that helps you find the optimal balance between memory and speed.
Configuring a PHP Lambda function to work with SQS and SNS
Out of the box, Symfony’s Messenger component doesn’t work in a serverless context. A Lambda function doesn’t “subscribe” to a queue, rather it is “cold” (not running) until triggered. In AWS Lambda, you can define SQS queues to serve as a trigger for your function. When a new message arrives, the Lambda function gets “warm” and runs.
However, Symfony messenger cannot consume messages like this. You need something to bridge the gap between AWS Lambda and Symfony. Luckily, there’s the Bref framework which is designed to solve exactly this kind of problem. In our case, we used Bref’s Symfony Messenger bridge to consume the incoming message from SQS. We also used the same bridge to broadcast notifications via AWS SNS.
Testing Lambda functions locally
We didn’t want to debug our functions in AWS since this would incur unnecessary costs, so we needed to adapt our local test environment.
We already had a Docker compose file to spin up a local testing environment for the container-based system.
When adapting the environment for AWS Lambda, we created a Makefile to simplify the process of spinning up the required containers. To understand the components of the local environment, take a look at the variables we defined at the top of a Makefile:
APP_CONTAINER_NAME = “cdh-app” SQS_CONTAINER_NAME = “cdh-sqs” SNS_CONTAINER_NAME = “cdh-sns” DB_CONTAINER_NAME = “cdh-db”
These variables are specific to the customer data hub.
The Lambda functions are stored as PHP files in the “cdh-app” container and are invoked with the Bref local command. We also had containers to simulate the SQS queue, the SNS topic, and the data hub’s PostgreSQL database.
Database migrations
Whenever we deployed a new version of the application, certain database migrations were defined as part of the deployment configuration. When switching to Lambda, we created a dedicated Lambda function that was responsible for the migrations. This function was then triggered whenever a new version of the application was deployed.
Observability with AWS Lambda functions
We used Datadog to monitor the whole application when it was running in Fargate, and we continued to do so after switching to AWS Lambda. However, we had changed the way Datadog was integrated.
As you might remember, it costs us a lot to Datadog Docker images through the NAT Gateway. These images were required to run the Datadog agent in ECS. With AWS Lambda, we no longer needed to use the Datadog agent and instead relied exclusively on the Datadog Cloudformation integration.
Cloudformation lets you provision your AWS Stack with one template, and the Datadog Cloudformation integration allows you to include Datadog resources in that stack.
The main Datadog resource we were using was the Datadog AWS Integration. This integration extracts all the metrics available in CloudWatch — Amazon’s native observability tool. These metrics include the AWS Lambda metrics.
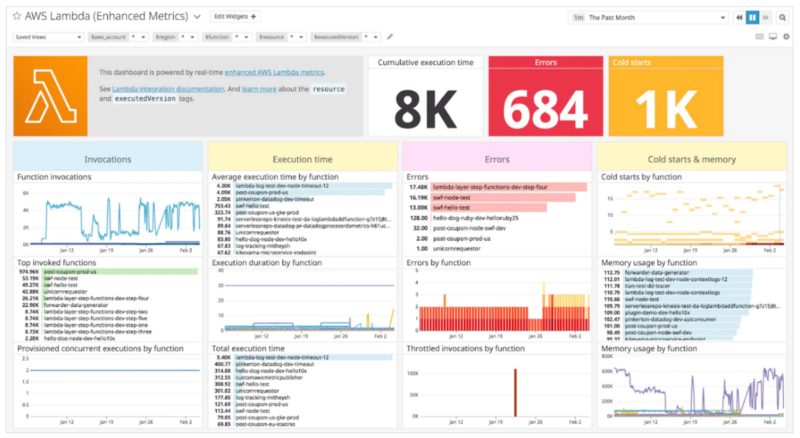
We prefer Datadog as an observability tool because the Dashboards are much nicer. Here’s a screenshot of an AWS Lambda Dashboard from Datadog’s own blog post on monitoring Lambda.
The results
After we had the system running for a couple of months, we were able to reduce the infrastructure bill from $2,550 before tax to around $773.
The costs were reduced so dramatically because of two main factors:
- We eliminated the large volumes of data flowing through the NAT Gateway (external images are no longer required at build time)
- We stopped using AWS Fargate, reducing vCPU usage and the premiums paid for vCPU under Fargate.
(we still needed an EC2 instance for the Bastion server, which allowed admin users to securely access and manage the database)
Here’s an overview of the new architecture with the reduced volume of data that needs to flow through the NAT Gateway.
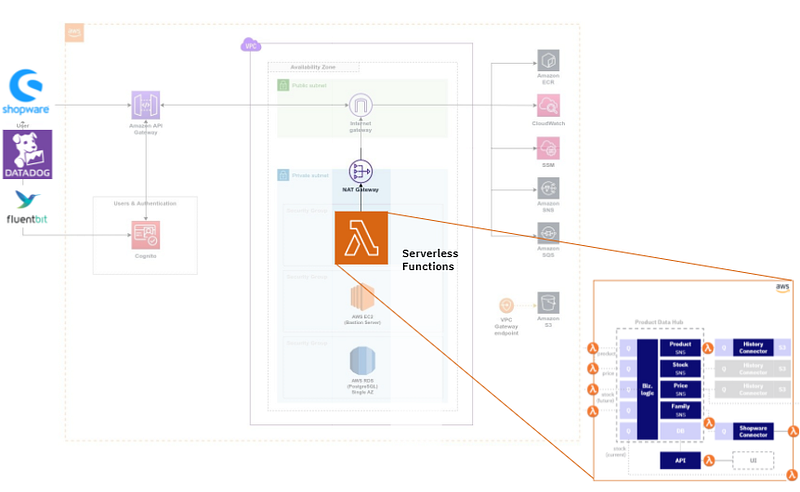
We could have saved even more money if we’d used Amazon Aurora serverless as our database engine instead of PostgreSQL. Amazon Aurora Serverless is significantly cheaper if you only have occasional spikes in traffic to your database. This was certainly the case for our application, but since the database only costs us $100–150 per month, the effort required to change the database engine would have hardly been worth it. But if you’re dealing with larger volumes and sporadic load, it might be worth considering.
The Takeaway
In our experience, startups often choose Fargate as their go-to solution because everyone says it’s easy to manage. However, often their applications are too small (in terms of load and complexity), even for Fargate. They could have saved a lot more money by starting off Lambda instead. Hopefully, this case study helps some of you from making the same mistake.
And remember, once your startup picks up momentum, you can always move left in the scale of complexity — to Fargate or managed Kubernetes. Moving from a simpler solution to a more complex one is a lot easier than going from complex to simple.