Exponential growth is exciting but can come with an unwanted side effect — rushed technical decisions and technical debt. Some technical debt is fine as long as it’s handled strategically. But there’s one aspect of technical debt that always seems to get out of control: data orchestration and consistency. And we want to do something about it. We’re working on a free, open-source solution that helps smaller companies to keep their data consistent and to orchestrate it to different business systems.
I’ll be sharing our plans with you in a minute, but first, I need to clarify what I mean by data orchestration and outline the problem that we’re trying to solve.
Companies don’t think about data orchestration until it gets out of control
Some people call data the “lifeblood” of a business. I’m not a huge fan of this cliche (is there any other kind of blood?), but when applied to operational data, the metaphor is perfect. Unlike analytics data which can be processed in batch jobs, operational data needs to flow between systems in real-time (or close to real-time) transactions. Just like blood in the human body, if this data doesn’t flow efficiently and consistently to all parts of the business, that business starts to become sluggish and inefficient.
The term “data orchestration” describes a more holistic approach to managing data in a business. According to software vendor Openprise, they came up with this term in 2017, and it quickly caught on. By their definition, data orchestration is:
“…the automation of data-driven processes from end-to-end, including preparing data, making decisions based on that data, and taking actions based on those decisions. It’s a process that often spans across many different systems, departments, and types of data….The term “data orchestration” implied that different groups and systems worked together as part of a carefully choreographed business process.”
Now that we have a rough idea of what data orchestration entails let’s take a look at one of its biggest challenges: data consistency. For all you database admins, I don’t mean the “C” in the ACID acronym — I mean consistency as it relates to business objects.
For example, let’s compare data to a language. Ideally, each team in a business should speak the same language, albeit with a different accent rather than a completely different dialect. When dialects evolve, it gets confusing. Especially when people understand different things for the same term.
Take the term “customer”. I was once baffled when a colleague declared that “we need to respond to our customers faster”. I had just joined a team that had nothing to do with customer support. In fact, the person was talking about answering JIRA tickets lodged by other departments. Since we were providing a service to other teams (training), they referred to other teams as “customers”. Such misunderstandings get reflected in field names and data schemas (i.e. a free-text “customer” field in JIRA).
In his book “Designing Event Driven Systems”, author Ben Stopford explains what can happen when you let these semantic issues go unchecked.
Consider two companies going through a merger.There will be a host of equivalent datasets that were modeled differently by each side. You might think of this as a simple transformation problem, but typically there are far deeper semantic conflicts: Is a supplier a customer? Is a contractor an employee? This opens up more opportunity for misinterpretation.
So as data is moved from application to application and from service to service, these interactions behave a bit like a game of telephone (a.k.a. Chinese whispers): everything starts well, but as time passes the original message gets misinterpreted and transforms into something quite different.
Some of the resulting issues can be serious: a bank whose Risk and Finance departments disagree on the bank’s position, or a retailer — with a particularly protracted workflow — taking a week to answer customer questions.
So we can see that solving the data consistency problem is crucial for a business and its component systems. But how exactly do you tackle it?
A hard problem to solve
In his 2009 post “TwoHardThings”, Martin Fowler popularized the quote, “There are only two hard things in Computer Science: cache invalidation and naming things.” (originally attributed to Phil Karton). With regards to data, I would expand on that last part and say “naming things and shaping data”. Specifically, data structures that describe business objects such as “customer”, “order”, and “product”. Or domain-specific objects such as “patient” (healthcare), “device” (IoT), or “claim” (insurance).
Naming and shaping aren’t just about working out the fields in a database table. It’s also about an object’s attributes and the shape of the data. Data often gets squashed into an ill-fitting mold that is shaped by how a specific system or database vendor wants you to see the world. Shaping means ensuring that an object reflects its business domain independent from any single system.
For example, if you could design a customer object that could be useful for all systems and their owners, what would that object look like? What attributes do you want a customer object to have, and how should these attributes be organized? One system will need to know about email addresses and marketing preferences, another system needs a customer’s physical addresses, and yet another system might make decisions based on the loyalty schemes that the customer has opted into. You get the picture.
Some people rightfully might ask why on earth you would want to design an object like this. It’s perfectly natural for each system and team to have different ideas of what’s interesting about a customer or an order. Indeed, this question is understandable if you have a classic point-to-point architecture. Shop front passes order details to the fulfillment system. Shop front passes customer preferences to the marketing system. Shop front polls shipping system for order status. Each system only needs to worry about what its communication partner needs. Which is great until your architecture starts to look like this.
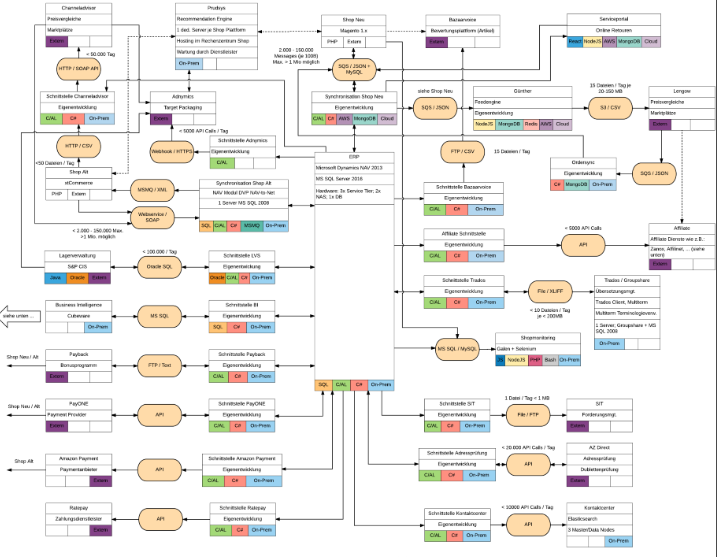
What’s bad about this picture? Obviously, it’s very complicated. It’s the classic “spaghetti architecture” that we use when we want to criticize point-to-point architectures. There’s some middleware there, but there’s still a lot of direct communication. This isn’t bad in itself. Point-to-point connections are fine if your system needs a quick response (such as payment processing). So this architecture is OK….until you want to change something.
And fast-moving startups are often changing systems. They need to change systems to match their particular growth phase and IT budget. It could be the CRM, the ERP system, the CMS, you name it. It’s probably going to change in the near future. And as any CTO will tell you, it’s no fun trying to replace a component when your architecture looks like a cat threw up on a whiteboard.
That’s why you need to integrate systems with a view to throwing them away later. But every time you throw something out and replace it, you usually have to renegotiate your business objects — your definitions of a customer, product, or whatever it is that’s affected. This process gets boring and expensive
Moving the Data to the Center
To make architectures more modular, companies usually try to centralize in some way. This can have a positive effect on how data is managed because it has to flow through a central “heart”. More people have an overview of how data is used and shaped.
The Enterprise Service Bus (ESB)
For example, many companies opt to decouple tightly connected services and have them communicate asynchronously through some kind of central ESB. This pattern is a step in the right direction because much of the business logic is then centralized in the ESB. One team has to administer this centralized system, and they need to understand how data flows throughout the business. Order data coming from system A needs to get transformed and routed to system B. It’s then somewhat easier to replace System B with another system.
What’s not so good about this pattern is that too much logic and functionality gets centralized, and very few teams know how their data gets through the sausage machine.

Sure, they get a nice sausage, but how did it get made, and what went into it? Did the machine blend in some eyeballs, tongues, or hog jowls? Nobody knows. All of the business logic that transforms and routes data is now owned by a precious view. This makes teams highly dependent on “the machine”, and no one wants that. Development teams need to be able to work independently.
Message Brokers
Another “lighter” pattern is to use a system that focuses just on the message brokering parts, such as Apache Kafka or RabbitMQ. This pattern is popular with highly event-driven applications where several systems need to react to an event, such as a “like” button being clicked or a mobile device entering a certain region. In this case, most often, business logic is handled by the subscribing systems rather than being centralized.
The good thing about both middleware patterns is that they force you to think about data consistency on a wider scale. In the case of Kafka or RabbitMQ, you have no idea what system is consuming your data, so you need to guarantee that the messages will adhere to a consistent schema.
To ensure data consistency, you can use canonical schemas or service contracts as long as you have the tools to validate the data being produced. For example, the Confluent platform provides this kind of functionality. Confluent is a managed Apache Kafka platform that features a schema registry. This registry basically serves as a centralized store for your business objects, but it also enforces compliance with a specific data structure.
Here’s a rudimentary example of a schema from their documentation:
{
"namespace": "example.avro",
"type": "record",
"name": "user",
"fields": [
{"name": "name", "type": "string"},
{"name": "favorite_number", "type": "int"}
]
}
It’s a user record with two fields: “name” and “favorite number”.
Once you have a schema for your business objects and any new systems are integrated, you can say, “oh, this message contains order data and uses order schema V1. I will adapt to this schema and use it to process all future order-related messages”.
A system like Confluent would be great to solve the data problem I’ve been discussing — if only Kafka wasn’t so complicated. Of course, Confluent evolved to address this very issue, and they’ve done a great job at making Kafka more accessible. But it’s still tricky if you don’t know Kafka at all, and it obviously costs money. And in our opinion, it has more features than a typical early-stage startup really needs.
Data Hubs
Another middleware pattern is to use some kind of data hub that can transform and harmonize data from disparate sources. In this case, the data is persistent and available for both analytics and business operations. But it doesn’t take care of data distribution itself and instead depends on APIs or message brokers to do this.
Unlike a data lake or a data warehouse, you can integrate a data hub with a service-oriented architecture to facilitate real-time transactions. It’s a central repository that is constantly being read and written to by multiple systems. This also allows it to meditate and validate the operational data that flows through your architecture.
Companies like MarkLogic, Cloudera, and PureStorage all produce data hubs that have very powerful features, such as the ability to store multiple data models (relational, NoSQL, etc.) whilst still allowing you to index and search the data. This is all going in the right direction, but again, we don’t think startups need all of those powerful features. We think they need something much dumber and cheaper (free and open-source, in fact!).
There needs to be a product for startups that are less mature in terms of their enterprise architecture. Something that allows them to keep their data synchronized, consistent and centralized without imposing a whole bunch of new integration patterns at once. So we decided to build a smaller piece of middleware that retains an opinionated view of data without throwing people in at the deep end of event processing or data orchestration. Once people are comfortable with this new way of looking at data, it’s not so hard to introduce a more powerful platform such as Confluent or MarkLogic when the company becomes more mature. Naturally, companies could also keep our lightweight solution long-term if it still works for them.
Herbie: a lightweight, open-source data hub
Maybe you’ve started off with a fairly monolithic web app but now find yourself adding more systems and feel like you’re drifting into spaghetti territory. You’re too busy to devote much of your time to architecture, but you’re concerned about the technical debt you’re accumulating. We’re designing Herbie to help you address that debt without too much of a steep learning curve.
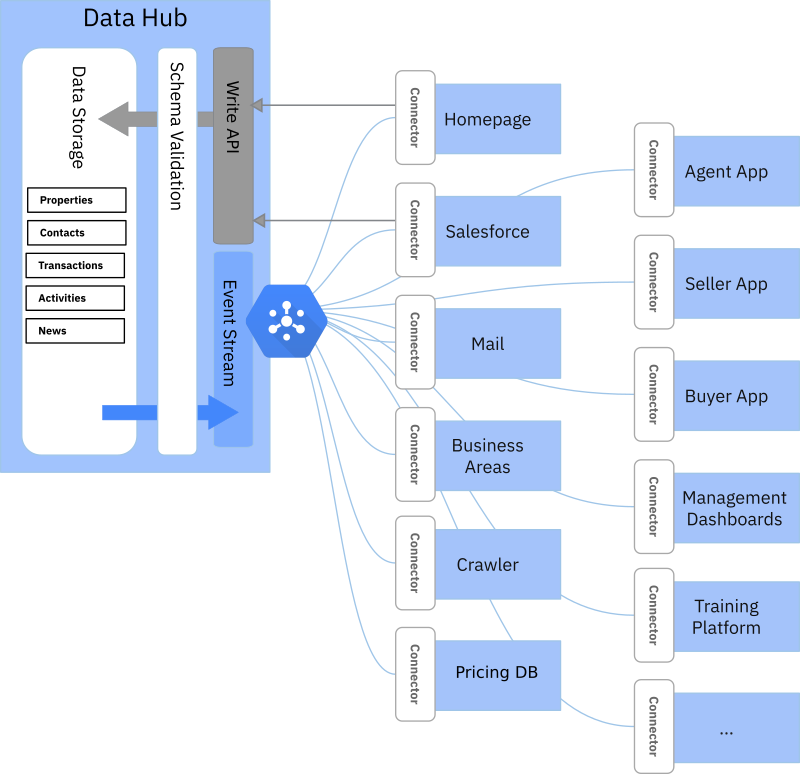
The idea for our project is to provide a minimal set of features required to support the process of data orchestration. Its main job would be to act as a central location for storing business objects. But it would also include a governance component.
Any system could write data to the data hub through an API, but the data would have to adhere to a schema that you define. So our system would have some kind of schema registry and validation mechanism. You could then use those schemas to define and harmonize your business objects.
We don’t need it to support multiple data models. JSON is just fine for us. A business object would come in as JSON and be validated against a JSON schema. The JSON data would be self-contained. That means that anything required to understand the business object would be in the file. For example, consider what you need to get a full picture of a specific order. You need customer details, delivery addresses, product details, and so on. In a relational database, that would require a complex set of queries and joins. For our project, you would just dump all of that data in a JSON file that adheres to the “order” schema and write it to the database.
We also don’t want some kind of data store which people can connect to and start querying directly. That job should be left to other systems. Instead, data distribution would be event-driven using a simple Pub/Sub technology. If you have a system that is interested in orders, it can subscribe to changes in order business objects. Whenever a “publishing” system uses the write API to write an order object, your subscriber system will get a message that includes the order JSON. You can then build a connector that transforms that JSON into whatever you want. Maybe you only care about a subset of the data, fine, just extract what you need. Due to the schema validation, you can build a connector with the assurance that the message will always come in a consistent format.
Unlike Kafka, we don’t want to store and replay events. If order #45789 got changed 10 times, we only persist its most recent state. Like I said previously, if your system is interested in order events, it will get notified. But it’s up to the subscribing system to persist the events if you want a proper event log.
Although data distribution is highly event-driven, we still want to support some kind of batch functionality. You should be able to say “given me all business objects which have the type “order” and put them into your analytics application. Just don’t expect to be able to extract orders based on their attributes. That’s what your reporting system is for.
Finally, we want the system to be secure but easy to set up. It should use a framework and language that is widely supported and easily understood — even for developers who have no previous experience with it. To meet these criteria, our go-to framework is Django which is based on Python — one of the most popular and accessible languages for anyone working with data.
You can find a prototype for our project in GitHub, but we’ve still got a lot of improvements to merge — so bear that in mind when looking around.
In any case, I hope that I’ve made it clear to you why we think this is worth doing. We want to solve the problem of bad data orchestration without introducing the complexity and cost that come with more powerful solutions.
In a follow-up post, I’ll go into more detail about the technology behind our solution. I’ll also be writing more about how to identify and define your business objects (we’ve gone through this exercise a couple of times with different companies). If you’re interested in this subject, make sure you subscribe to our publication or follow us on LinkedIn. Also, if you’ve built something similar or are thinking about doing it, we’d be interested in your thoughts.
PS: Why did we call it Herbie? Funny you ask, it’s a long story.