By Andreas Helbig
Today, we’re thrilled to announce that we led Anyline’s $12M Series A. The team convinced us throughout our discussions with a deep understanding for the problem they’re solving, their technological edge and stellar execution to date. We’re looking forward to the journey ahead and to partnering with Senovo, Hansi Hansmann, Push Ventures and all others!
Anyline, an SDK for OCR — what!?
This is a short, but abbreviation-heavy description for what Anyline does. To get a little more specific: whenever an enterprise wants to incorporate any image-to-text functionality into one of their mobile apps, Anyline provides them with what they need. On the technology side, this includes two main aspects — pre-defined core products and the Anyline platform:
For the pre-defined core products, Anyline provides a full ML model tailored to the specific use case, with little to no model training required for each individual customer. These use cases include mobile license plate scanning, serial number scanning in factories, utility meter reading, KYC passport/ID scanning, voucher code scanning, etc. It is Anyline’s core offering and very much an enterprise product, having convinced DAX-30 and Fortune 500 companies as well as government authorities. Here you can see the product in action, solving the technologically difficult case of reading tire identification numbers — curved font, black on black.
The newly-launched Anyline platform is making Anyline’s internal core OCR model available as self-service: customers can train new use cases and deploy them within hours, and without dedicated machine learning skills. In the background, the Anyline platform is training multiple neural networks, which creates a computer vision pipeline and then validates it. This is opening up new use cases and new customer groups for Anyline.
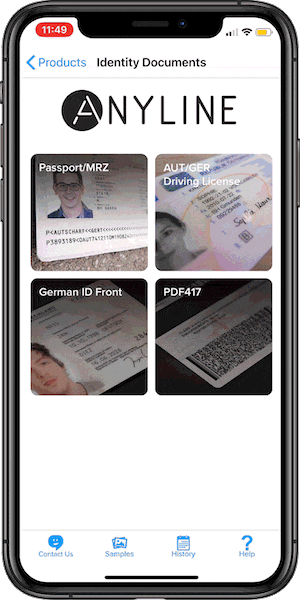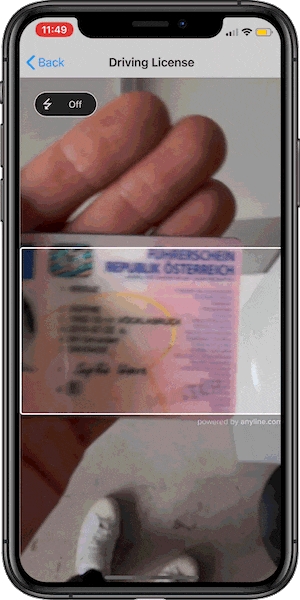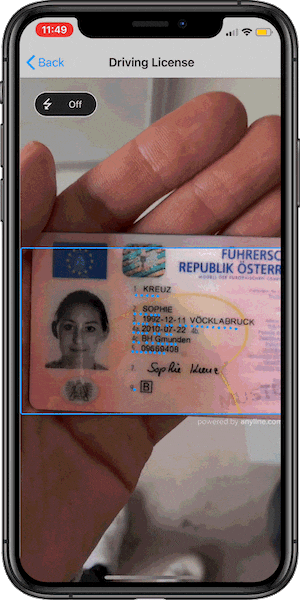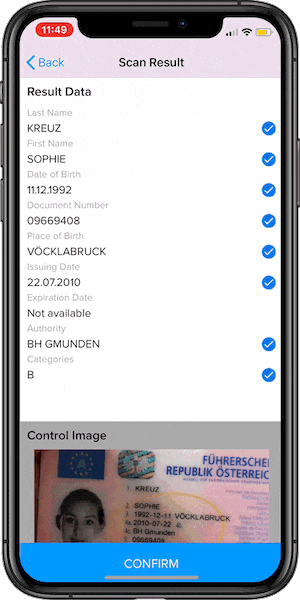
It’s maybe not obvious, but that’s exactly why it’s great
OCR is definitely not an entirely new invention — the roots of the technology date back to 1870. Also, there’s tons of open-source software available — Tesseract being the most prominent one. Furthermore, both Amazon and Google are providing OCR technology available to their customers via their cloud platforms. So why is this Anyline thing actually any different?
One part of the answer is: They’re better. 🙂 Anyline’s accuracy outperforms other, more generic, solutions by far. This is a result of having a dedicated focus towards mobile — Anyline works with many camera types — and towards the type of text they’re detecting: Anyline detects text character by character, not word by word. Therefore, Anyline is focused on all kinds of serial number use cases, with a great need for accuracy on a char level. In order to achieve this, their technology doesn’t rely on other cues, e.g. combining chars to a word that makes sense. All of this combined makes Anyline simply more suitable for many use cases, especially in the enterprise segment.
The other part of the answer, arguably even more important for the long-term defensibility, is Anyline’s ability to integrate with the customer: Anyline technology can be deployed on the customer’s terms — it’s an enterprise product. No police force would run license plates over the Google Cloud, and no enterprise customer would have their own IT department build OCR functionalities based on open-source tools if Anyline provides a better technology offering and an easy integration.
To summarize: Solving OCR for enterprises is certainly not the futuristic Stanford-research-detecting-emotions-of-passengers-in-driverless-cars type of AI, but it delivers tremendous value to customers right now. As a result of the “non-sexiness” and the competition in broader OCR, investing in Anyline might not be considered an obvious investment — and this is great the way it is. The deeper we went into their technology stack, the more we fell in love with the opportunity — and the team behind it.

Horizontal AI? Vertical AI? T-Shaped?!
A broader observation that we made along the internal discussion: our AI investments so far were mostly in vertical AI, i.e. a specific ML model applied to a specific use case. Examples are micropsi = Computer vision-based control system for industrial robots or Comtravo = NLP for corporate travel. Anyline is difficult to categorize, as the OCR model per se is vertical-agnostic: the platform provides the picks and shovels for OCR models (therefore, this component is horizontal AI) but the specific predefined use cases are definitely vertical applications. Overall, we’re still not sure how to categorize the business into the classic, maybe over-simplified, VC categorization. It’s both vertical and horizontal, so maybe T-shaped AI? (Also, how do you discuss this without sounding like a douchebag Twitter VC?)
This type of AI startup has several implications — e.g. a necessary clear differentiation to more generic tools of Google/Amazon/Facebook etc. and to open-source tools, which are also typical for horizontal AI. Additionally, it might be that each one of the vertical use cases alone is not large enough to sustain a large VC case type of company, but the combination of use cases is — and this combination is enabled by the horizontal technology component.
Other examples for companies with similar characteristics are Valossa for detecting video content or Affectiva for detecting human emotions. Happy to discuss with fellow investors on how to map out the space and what further implications are — or even if mapping makes sense at all. 🙂